Saya lanjutkan pembahasan tentang Decision Tree (DT). Tahapan yang dilakukan adalah dari dataset yang telah memiliki label dilakukan training yang menghasilkan model classifier. Model ini kemudian digunakan untuk melakukan prediksi terhadap instance yang belum memiliki label.
Beberapa pertimbangan kapan menggunakan algoritma DT:
- Instance dapat dideskripsikan sebagai pasangan atribut dan nilai
- Fungsi target memiliki nilai diskret
- Diperlukan Hipotesisnya yang disjunctive (tidak banyak keterhubungan)
- Bila training datanya ada noise atau ada data yang hilang
Contoh
Diagnosa medis, diagnosa alat, analisa resiko kredit, pemodelan kecenderungan penjadwalan
Algoritma DT untuk memilih main loop
- Pilih A: Atribut terbaik yang jadi node
- Tentukan A sebagai atribut decision pada node
- Pada setiap nilai A, buat turunan (descendant) dari node
- Urutkan contoh data training ke daun (leaf node)
- Bila contoh data training sudah terklasifikasi dengan baik, maka berhenti, bila belum ulangi lagi dengan node daun baru
Maksud terklasifikasi dengan baik, misalnya datanya tidak tercampur yang positif dengan negatif (homogen)
Nilai atribut akan digunakan utnuk memilah-milah dataset. Bagaimana cara untuk memilih atribut terbaik? Beberapa caranya adalah:
- Random: pilih atribut secara acak
- Least value: Atribut dengan memiliki kemungkinan nilai yang paling sedikit
- Most Value: atribut yang memiliki kemungkinan nilai paling banyak
- Max Gain: atribut yang memiliki information gain terbesar
Metode pemilihan dengan max Gain adalah yang banyak digunakan contohnya algoritma ID3.
Idealnya atribut yang baik dapat langsung memisahkan sampel menjadi menjadi bagian yang semuanya positif dan semuanya negatif (homogen). Pohon diusahakan seringkas mungkin tapi mampu mengklasifikasikan dataset dengan baik.
Entropi adalah mengukur tingkat ketidakmurnian dalam satu grup. Rumusnya adalah:
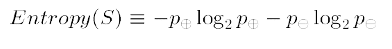
dengan S adalah sampel dari data training,
p adalah jumlah sampel positif dalam S
n adalah jumlah sampel negatif dalam S
Rumus umumnya entropi adalah :
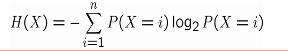
Information Gain menjelaskan seberapa penting atribut dari fitur vektor. Rumus Information gain dari X dan Y adalah:
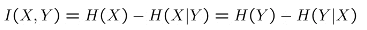
Information Gain adalah mutual information dari atribut A dan variabel target Y.
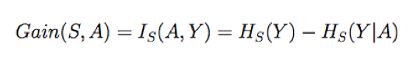
Gain (S,A) adalah besarnya penurunan (reduksi) entropi setelah sampel dipilah-pilah berdasarkan nilai dari Atribut A tersebut
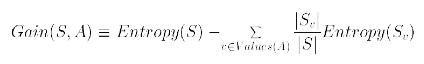
Atribut yang dipilih adalah yang memiliki nilai Gain paling besar. Kelemahan Information Gain adalah cenderung memilih atribut yang jumlah nilai atributnya lebih banyak dan memotong menjadi subset yang lebih kecil. Untuk mengatasi masalah ini bisa digunakan metode normalisasi dengan Quinlan Gain Ratio.
ID3 melakukan pencarian heuristik pada space hipotesis. Pencarian berhenti pada tree terkecil yang dapat diterima, berdasarkan prinsip occam razor. Occam razor cenderung memilih hipotesis yang sederhana yang bisa menjelaskan fenomena pada data.
Proses pencarian hipotesis
- Ruang Hipotesis decision tree lengkap (fungsi target pasti ada)
- Hanya memilih satu hipotesis
- Proses pencarian hipotesis tidak melakukan backtracking
- Proses pencarian hipotesis berbasis statistik (tahan terhadap noise atau labelnya salah)
- Algoritma pencarian cenderung untuk mencari pohon yang pendek (inductive bias)
Pohon yang baik adalah pohon yang mampu melakukan generalisasi dengan baik. Backtracking itu balik lagi. Didapatkan lokal optima.
Sampai disini dulu. Semoga Bermanfaat!