Saya baru dengerin webinar inside the lab yang diadain sama meta. Disini Meta (alias facebook) cerita tentang gimana mereka ngembangin berbagai teknologi baru. Sesi pertama pengantar dari Mark Zuckerberg.
Om mark cerita tentang teknologi Meta, yang ngegabungin AR,VR dan AI. Terus dia share berbagai macam riset yang lagi dikembangin diantaranya adalah Cairoke. Proyek ini tentang natural language, kita bisa interaksi dengan personal asisten virtual kita. Contohnya dia nampilin video tentang robot builderbot. Robot yang dia gunakan untuk bikin berbagai fitur di metaverse hanya dengan perintah suara. Contohnya bisa dilihat di video berikut:
Cairaoke ini punya 4 teknologi: Natural Language understanding NLU, dialog state tracking (DST) , dialog policy (DP) , NL generation (NLG) dll. Teknologi ini Terus dia ceritanya juga lg ngembangin sistem dengan egocentric perception (AR/VR) serta tentang kelas baru generativ AI. Sistem AI yang dikembangin berbasis Self-supervised Learning nya om Yann LeCun
Trus meta juga lagi ngembangin sistem penerjemah baru, target dia bisa nerjemahin sampe 100 bahasa. Selain itu juga dia lagi ngembangin universal speech translator. Jadi klo dulu untuk nerjemahin bahasa prancis ke indo misalnya, itu dibikin dua langkah, prancis ke inggris dulu, trus inggris ke indo dan sebaliknya. Dia pengen bikin itu langsung jadi satu langkah aja, prancis ke indo.
Om mark juga nampilin contoh hasil risetnya yaitu FastMRI. Ini untuk ngebantu hasil scan MRI, jadi hasil gambarnya di enhanced dengan AI. Maksudnya pake teknologi vision, gambarnya kayak dipertajam. contohnya ada di gambar berikut:
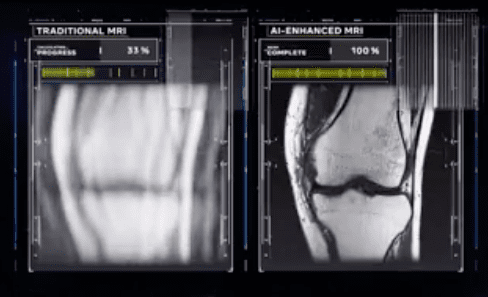
FastMRI: ai enhanced mri
Jerome Pesenti
Presenter berikutnya Jerome Pesenti dia cerita hasil riset meta banyak yang di share dalam bentuk opensource, contohnya pytorch library python untuk machine learning. Terus dia cerita lagi tentang SSL self supervised learning. Dia nampilin ilustrasi di gambar berikut.

Yang kiri anak kecil belajar dengan didampingi orangtuanya. Ini contoh supervised learning. Sementara di gambar kanan anak kecil belajar sendiri dengan dia jalan ke alam, dia melihat daun sendiri, mengenali apa itu daun dst. Ini contoh unsupervised learning, self supervised learning dst.
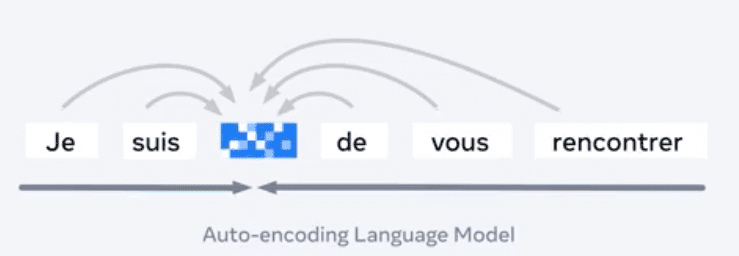
Contoh lainnya dia cerita tentang auto encoding language model. Di gambar terlihat ada satu kalimat yang ada satu kata yang hilang. Nah model SSL akan berusaha membuat model bahasanya dan mempelajari apa satu kata tersebut.
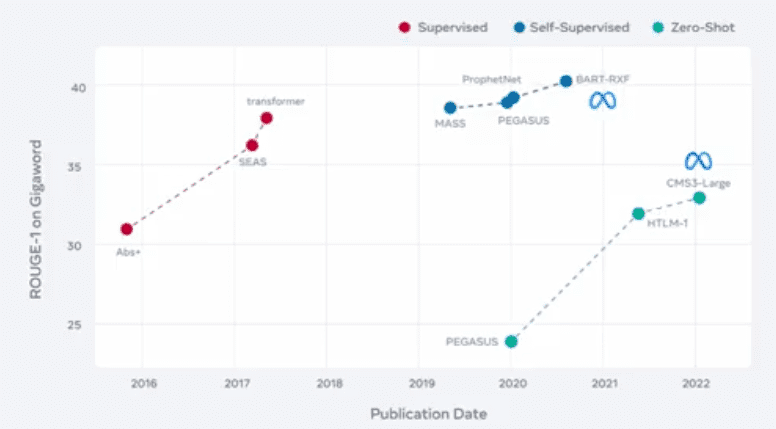
Kita lihat ada banyak riset di NLP saat ini yang di pretrained dengan SSL. Kita bisa lihat 5 tahun lalu yang digunakan adalah berbagai metode Supervised diantaranya abs+ ; seas; transformer. Sementara sejak tahun 2019 yang berkembang adalah model SSL seperti mass, prophenet, pegasis: 2020: bart-rxf. Baru kemudian tahun 2020 berkembang model zeroshot: pegasus, htlm-1-CMS3-large
Kelebihan SSL juga dia tidak task dependent. Jadi model yang ditrain dengan SSL bisa kemudian di transfer ke berbagai macam task lainnya seperti terlihat pada gambar berikut:
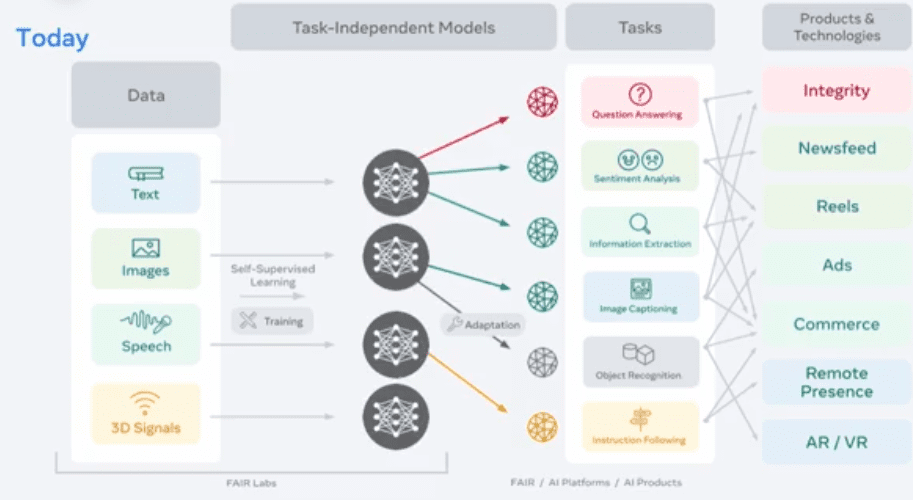
Misalnya model yang udah ditraining dengan SSL bisa dikembangin untuk task Question Answering (jawab pertanyaan) , sentiment analysis, information extraction, image captioning, object recognition, instruction following dll.
Selain di NLP, SSL juga udah dipake di vision. Contohnya pake transformer, SSL bisa memprediksi potongan gambar berikut ini jadi sebuah gambar yang utuh.
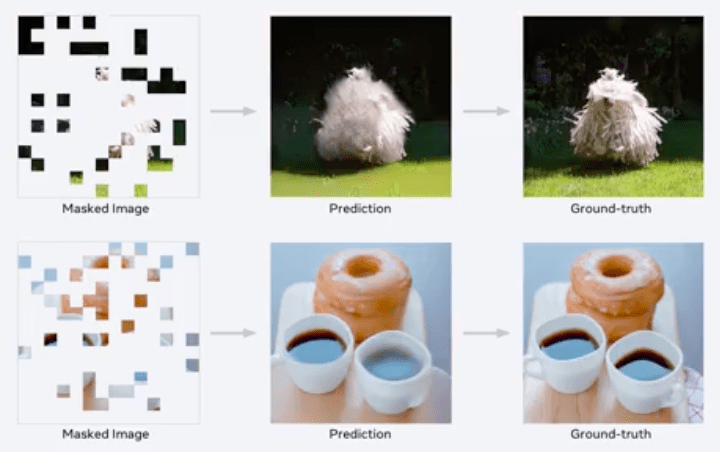
Performa SSL di Vision juga sudah mendekati performa supervised learning. Di grafik terlihat perbandingan performa supervised dengan SSL.
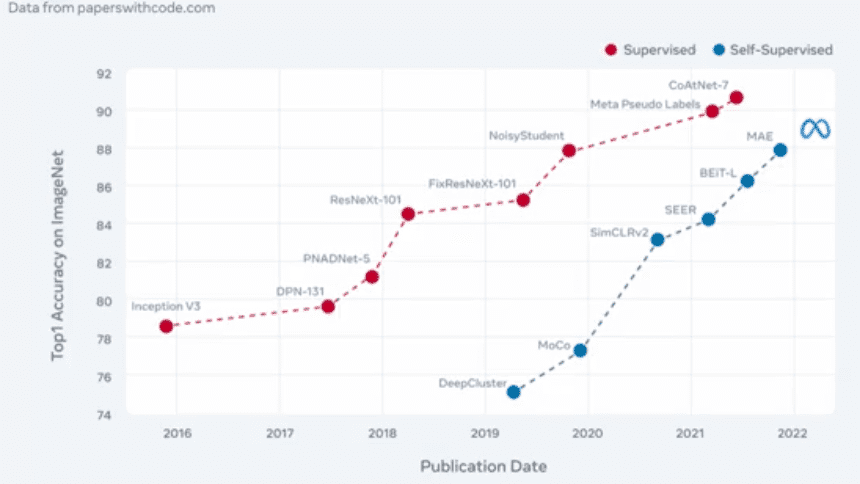
Kita lihat ada berbagai metode Supervised dari tahun ke tahun diantaranya inception, DPN131, pnadnet-5, resnet, fixresnext101, noisy student, meta pseudo label, oatnet-7 (92). Terus untuk SSL ada deepcluster, moco, simclrv2,SEER, BEit-l, MAE. Performanya waktu diuji di imagenet semakin mendekati tingkat akurasi yang supervised learning.
Seain itu untuk Speech recognition juga bisa dibandingkan performa supervised learnign dengan ssl
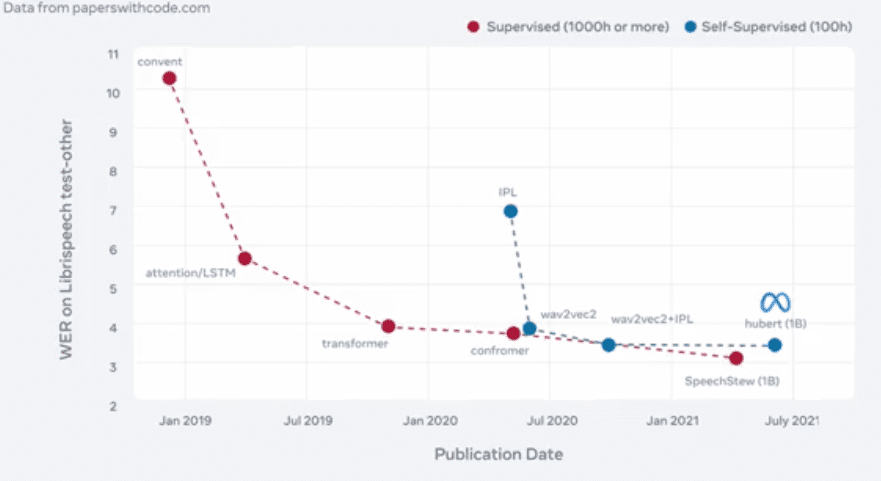
Di gambar kita bisa lihat performa berbagai metode supervised untuk speech diantaranya convent, attention, lstm, transformer, confromer, speechstew. Sementara itu untuk SSL bisa dilihat metode seperti wav2vec2,wav2vec2+ipl, hubert 18 sudah mendekati performa dari supervised learning.
Menurut Jerome kedepannya domain text, image maupun suara, akan gabung jadi satu model unified model yang multimodal seperti gambar dibawah ini:
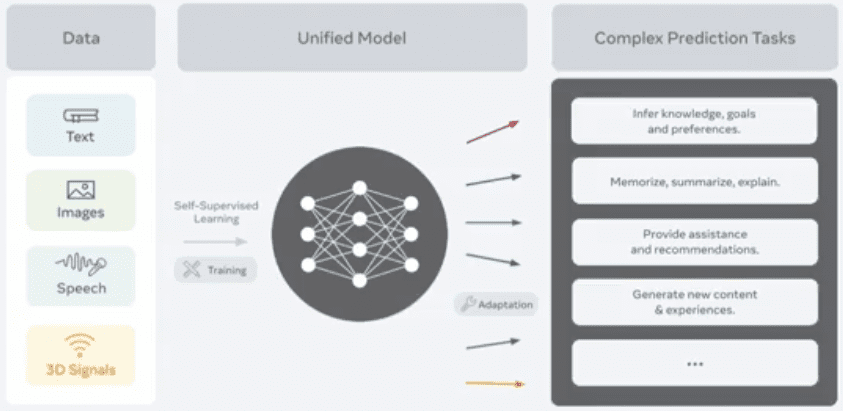
Jadi kita bisa memahami pembicaraan orang tidak hanya dari speech recognition tapi juga dari mimik wajahnya. Atau mengenali tentang posting di sosmed, gak hanya dari gambar, tapi dari video, maupun teksnya.
Sampai disini dulu, besok insyaallah akan saya lanjutkan dengan presenter berikutnya dari Joelle. Semoga Bermanfaat!