Saya baru dengerin kuliah Ishan Misra tentang Self-Supervised learning pada komputer vision. Menurut dia fokus penelitian komputer vision saat ini adalah bagaimana belajar representasi visual dari supervised data dan menggunakan representasi ini (weight modelnya) sebagai inisialisasi untuk task lainnya yang memiliki data berlabel yang sedikit. Proses memberi label pada data itu mahal, contohnya dataset Imagenet memiliki 14 juta gambar dengan 22 ribu kategori. Proses pemberian labelnya membutuhkan 22 tahun (human years)
Ada 2 teknik yang sedang berkembang untuk menangani kesulitan pemberian label ini, yaitu dengan:
- Semi-automatic process : misalnya dari hastag gambar, atau dari info GPS
- Self-supervised learning: menggunakan data dan dipelajari data, atau dengan prediksi bagian data dari bagian lainnya.
Pada komputer vision ada yang disebut pretext task. Pretext task ini adalah task self-supervised learning yang digunakan untuk learning visual representation. Tujuannya representasi yang dipelajari atau weight model yang diperoleh dapat digunakan untuk downstream task. Pretext task biasanya dilakukan pada sebuah properti yang ada pada dataset. Sementara downstream task yang dimaksud adalah task yang dilakukan machine learning seperti klasifikasi gambar atau deteksi obyek.
Contoh pretext task pada image:
- Prediksi posisi relatif sebuah patch pada gambar
- Prediksi tipe permutasi sebuah patch gambar, misalnya pada puzzle
- Prediksi jenis rotasi yang terjadi pada sebuah gambar

Pada gambar diatas contohnya ada dua patch pada gambar kucing, kotak biru diketahui posisinya dan kotak merah yang belum diketahui. Kemudian akan dilakukan prediksi posisi kotak hitam ada dimana. Ada 8 kemungkinan posisi dari kotak merah, sehingga menjadi klasifikasi 8 kelas menggunakan dua jaringan CNN dengan masing2 memiliki input kotak biru dan merah.
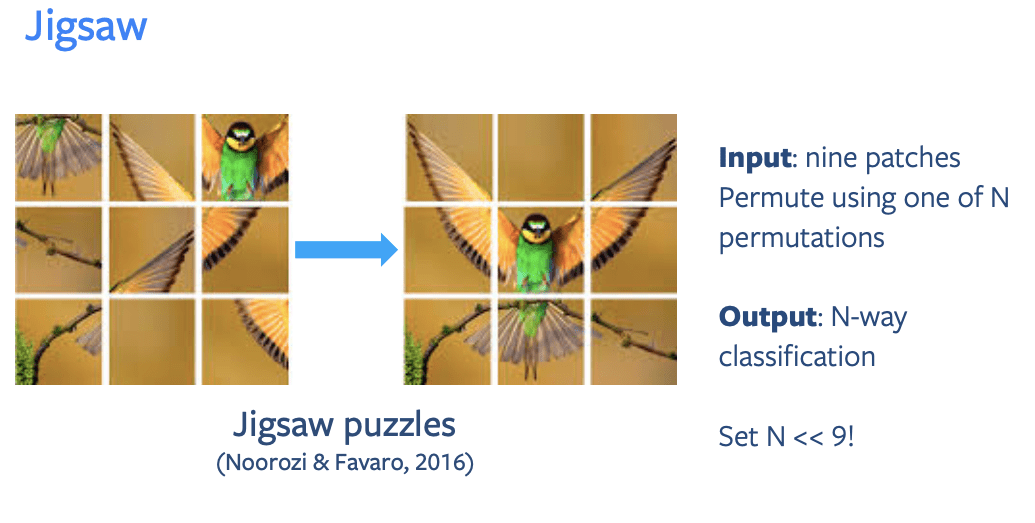
Pada gambar diatas ada 9 patch gambar, yang posisinya termutasi dengan salah satu dari permutasi N. Kemudian mesin akan melakukan klasifikasi N-kelas dengan N << 9!
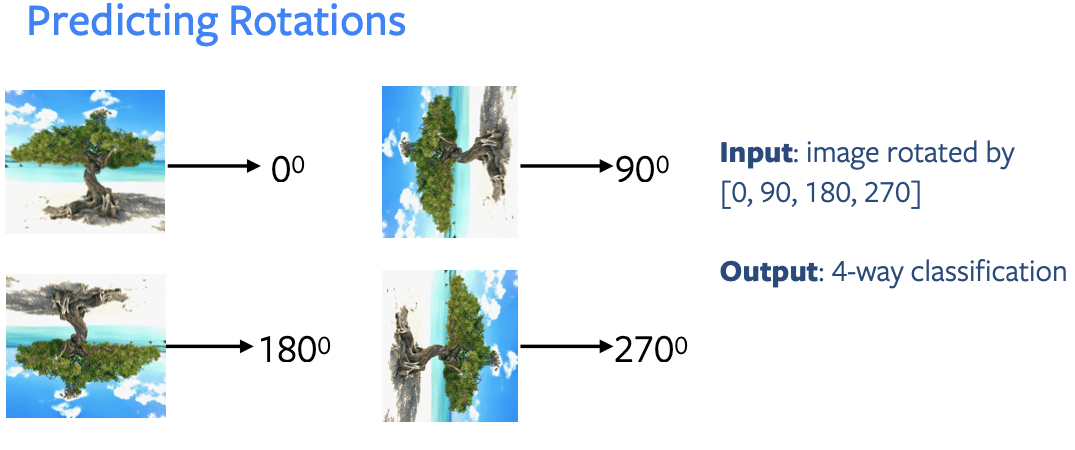
Pada gambar diatas mesin mendapat input sebuah gambar yang telah dirotasi sebanyak 0, 90, 180 dan 270 derajat. Mesin kemudian diminta melakukan klasifikasi 4 kelas untuk menentukan gambar tersebut termasuk dalam rotasi yang mana.
Namun ternyata ada mismatch antara pretext task dengan apa yang diinginkan pada task sebenarnya (transfer task). Sehingga apa yang diselesaikan pada saat pretext task tidak sesuai dengan final task.
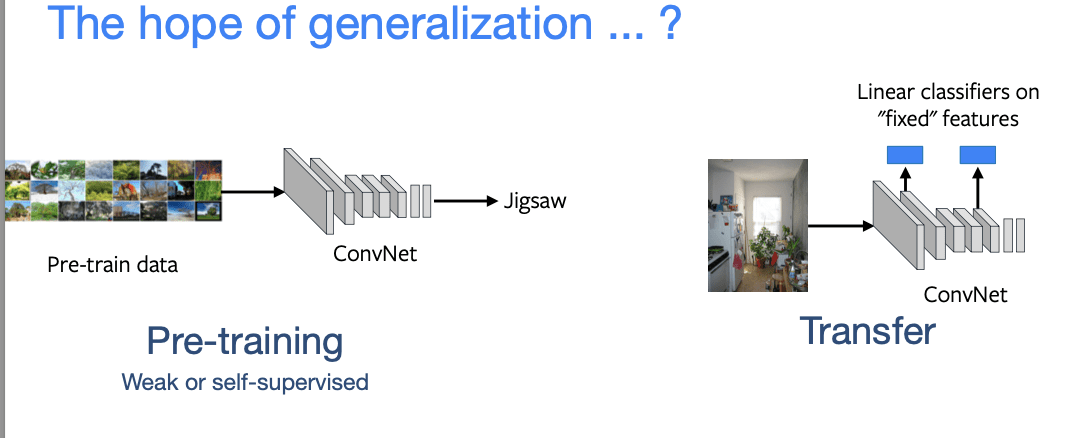
Contohnya pada gambar diatas, dilakukan pretraining dengan model jigsaw di bagian kiri. Kemudian hasil representasinya digunakan untuk transfer task di sebelah kanan, misalnya untuk deteksi obyek atau klasifikasi gambar. Hasilnya bisa dilihat pada gambar berikut ini:
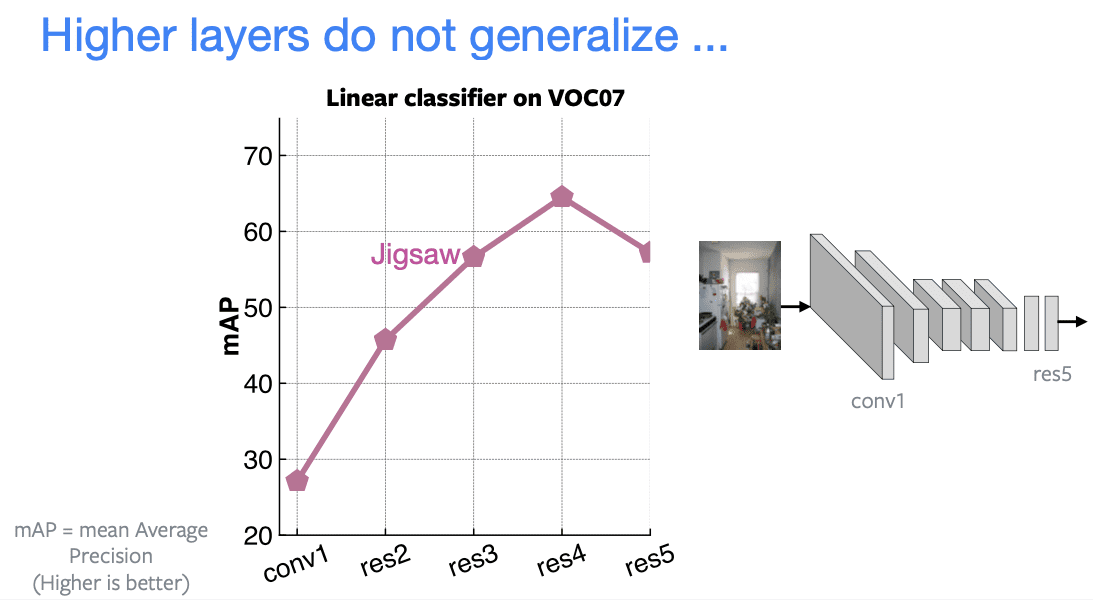
Terlihat dengan jaringan resnet5 akurasinya terus meningkat pada setiap layer, mulai dari convolutional 1, resnet2, 3 dan 4. Namun terjadi penurunan pada layer resnet 5. Karena model pada layer tersebut tidak berhasil melakukan generalisasi. Model tersebut hanya bagus untuk task jigsaw. Pada kasus ini, gak gak ngaruh berapa layer yg digunakan, polanya akan sama, yaitu ada penurunan performa di layer terakhir, karena dia spesifik ke task tertentu. Jadi walaupun misalnya layer 5 kita buang, hasilnya juga tidak akan memuaskan.
Lantas apa yang kurang dari pretext task (general proxy task) ini?
Sebelumnya kita harus mengetahui bahwa fitur pre-training harus memenuhi dua karakteristik dasar yaitu:
- Harus dapat merepresentasikan bagaimana gambar-gambar berhubungan (relate) satu sama lain
- Robust (kuat) terhadap faktor nuisance atau invariance. Maksudnya mesin harus mengenali obyek yang sama walaupun memiliki lokasi yang berbeda pada gambar, atau memiliki pencahayaan yang berbeda, atau memiliki warna yang berbeda.
Salah satu metode yang popular untuk self-supervised learning adalah untuk mempeljari fitur yang robust terhadap augmentasi data. Contohnya pada gambar rusa berikut ini:

Pada gambar diatas terlihat ada sebuah gambar rusa, yang telah diaugmentasi. Ada yang posisinya diubah, ada yang warnanya diubah bahkan ada yang resolusinya berubah. Sistem yang dibangun harus dapat mengenali bahwa gambar-gambar tersebut adalah rusa. Dengan berbagai variasinya.
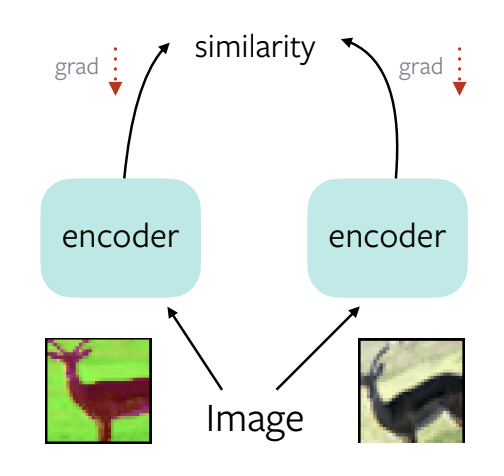
Pada gambar diatas, gambar rusa dgn berbagai teknik data augmentasi, di masukin ke encoder (assigning method), kemudian dihitung kesamaannya (maximize similarity), dicari nilai gradientnya dan dilakukan backpropagation. Pengukuran akan dilakukan menggunakan loss function (bisa dengan max cosine similarity, minimazi equal distance, dll). Jaringan akan mempelajari representasi dan menghasilkan representasi konstan untuk kedua augmentasi tersebut.
Inilah yang kemudian disebut sebagai trivial solution, dimana sistem robust terhadap invariance, namun menghasilkan fitur yang sama untuk semua input gambar. Sistem ini tidak dapat menangkap fitur yang mengenali bagaimana satu gambar berhubungan (relate) dengan gambar lainnya. Representasi ini menjadi tidak dapat digunakan untuk task downstream recognition.
Masih panjang kuliahnya, sementara sampai disini dulu, besok akan saya lanjutkan pembahasannya. Materinya bisa dilihat pada link berikut:
https://atcold.github.io/NYU-DLSP21/en/week10/10-1/
slidenya ada disini:
https://drive.google.com/file/d/1BQlWMVesOcioW69RCKWCjp6280Q42W9q/edit
Videonya:
Semoga Bermanfaat!