Saya lagi dengerin video tutorial dari CVPR 2021 tentang Self-supervised learning. Tutorial ini dibagi 6 sesi. Pada tulisan ini saya bahas sesi pertama yaitu introduction oleh Andrei Bursuc dari Valeo-ai.
Andrei cerita tentang perkembangan komputer vision saat ini yang mengandalkan Deep Learning dan supervised learning. Metode ini secara umum punya 3 tahapan:
- Mendefinisikan konsep apa yang mau dipelajari pada gambar
- Mengumpulkan sampel dalam jumlah besar dan beragam
- Training model dengan beberapa GPU selama berjam-jam
Cuman ada kendala untuk mendapatkan label. Perlu biaya besar, mahal dan lama. Selain itu juga rentan terhadap human eror. Contohnya untuk melakukan anotasi/pelabelan gambar di bawah ini untuk segmentasi semantik dibutuhkan waktu 1,5 jam. Bayangkan kalau kita harus melakukan anotasi untuk puluhan ribu gambar.

Saat ini dataset standar pada vision adalah ImageNet, namun belum ada dataset yang sebesar ImageNet khusus untuk obyek deteksi, gambar satelit.
Permasalahan lainnya adalah distribution shifts. Yaitu data terus berubah. Contohnya pada tren baju laki-laki dibawah ini. Tren pakaian terus berubah, sehingga perlu anotasi data baru, training lagi dst.

Selain itu perubahan lainnya adalah perkembangan teknologi yang terus berubah. Seperti perkembangan sensor dengan resolusi lebih tinggi. Sehingga perlu anotasi ulang, training ulang dst.

Sehingga kemudian muncul self-supervised learning. Pertanyaannya bisakah kita belajar label dari data secara langsung. Mendapatkan data tidak berlabel lebih mudah, namun metode supervised yang ada tidak bisa memahami gambar-gambar tersebut.
Deep learning membutuhkan data besar dengan label. Sementara data berlabel ini susah untuk didapatkan, dan biayanya mahal untuk melakukan labeling.
Walaupun kita memiliki data yang besar, masih ada beberapa kendala berikut pada metode supervised untuk mempelajari representasi yang baik.
Terjadi bias pada jaringan. Dari paper L.A.Gatys dkk “texture and art with deep neural network” neurobiology 2017, dia coba melakukan prediksi VGG-16 pada gambar dengan menambahkan tekstur buatan. Terlihat hasilnya gambarnya jadi aneh seperti gambar berikut.
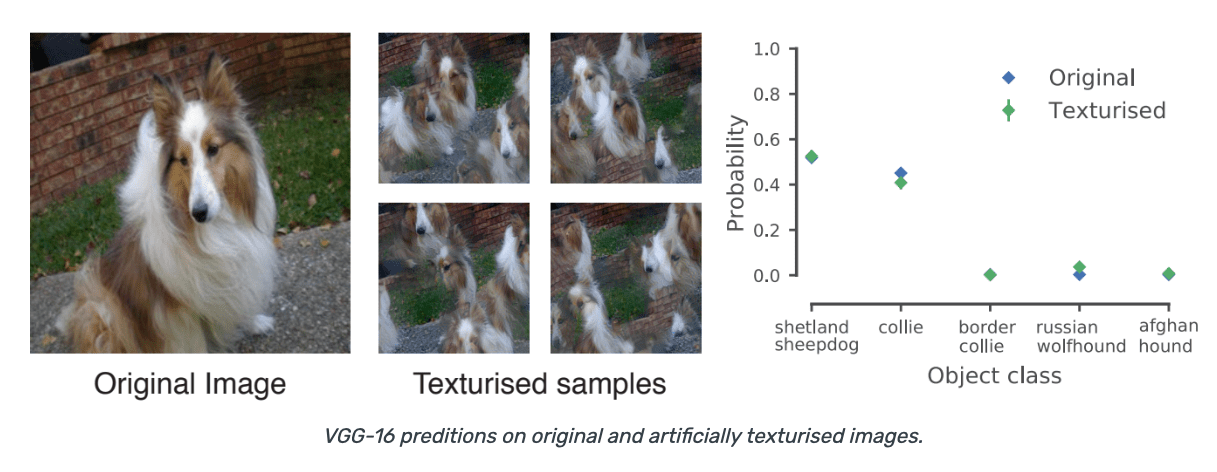
Contoh lainnya dari paper R.Geirhos dkk “ImageNet-trained CNNs are biased towards texture: increasing shape bias improves accuracy and robustnes, ICLR 2019. Dia melakukan klasifikasi gambar ImageNet dengan Resnet-50. Pada gambar terlihat dia menggabungkan dua gambar. Terlihat jaringan bias terhadap texture dari gambar.

Untuk mengatasi bias ini, Andrei cerita paper dari S.Jenni “Steering self-supervised feature learning beyond local pixel statistics” CVPR 2020. Jenni mencoba mengacak gambar, dengan tujuan statistik lokalnya tetap sama namun statistik globalnya berubah. Kemudian mesin diminta melakukan klasifikasi yang mana gambar yang benar dan mana yang sudah acak.

Training dilakukan dengan conv5, dan didapatkan hasil berikut:
- Pada model yang di pre-training dengan dataset ImageNet berlabel: akurasinya adalah 78%
- Pada model yang di pre-training dengan self-supervision akurasinya mencapai 85%
Menurut Andrei, untuk meningkatkan performa representation learning, tidak diperlukan fitur yang khusus untuk menyelesaikan sebuah task supervised tertentu. Namun fitur yang dapat digunakan untuk berbagai downstream task.
Contoh implementasi Self-supervised yang sukses adalah di bidang NLP. Misalnya model word2vec. Contohnya pada paper T.Mikolov dkk “efficient estimation of word representations in vector space, Arvix 2013; paper T.Mikolov dkk “Distributed representations of words and phrases and their composionality, NeurIPS 2013 dan J.Devlin “BERT: pre-training of Deep Bidirectional Transformers for Language Understanding, ArXiv 2018”. Mereka berhasil melakukan prediksi kata yang hilang pada sebuah kalimat. Maupun prediksi apakah 2 kalimat berurutan atau tidak, seperti pada gambar berikut:

Self-supervision adalah sebuah metode unsupervised learning dimana data yang menyediakan supervision signal, bukan orang. Langkah yang dilakukan pada supervised learning adalah:
- Mendefinisikan sebuah pretext task, dimana network dipaksa untuk mempelajari sesuatu yang kita inginkan. Umumnya bagian dari data disembunyikan, dan network diminta untuk melakukan prediksi.
- Feature/representasi yang dipelajari pada pretext task kemudian digunakan untuk downstream task berbeda, biasanya ketika beberapa anotasi telah tersedia.
Contohnya ada pada paper S.Gidaris dkk “Unsupervised representation learning by predicting image rotations, ICLR 2018”. Dia membuat sistem yang dapat melakukan prediksi rotasi pada gambar burung dibawah ini:
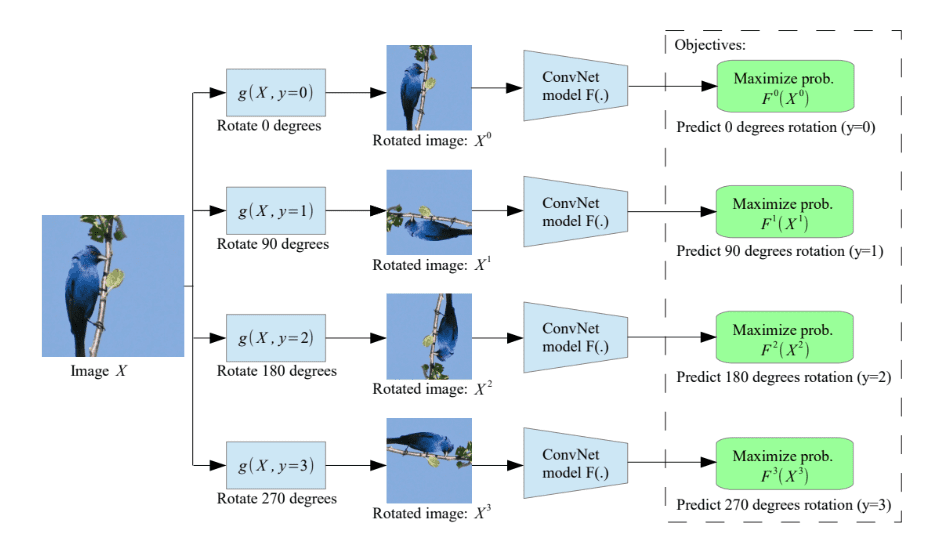
Gambar berikut ini adalah ilustrasi tahapan self-supervised untuk klasifikasi rotasi gambar dengan tahapan pretext dan downstream task:
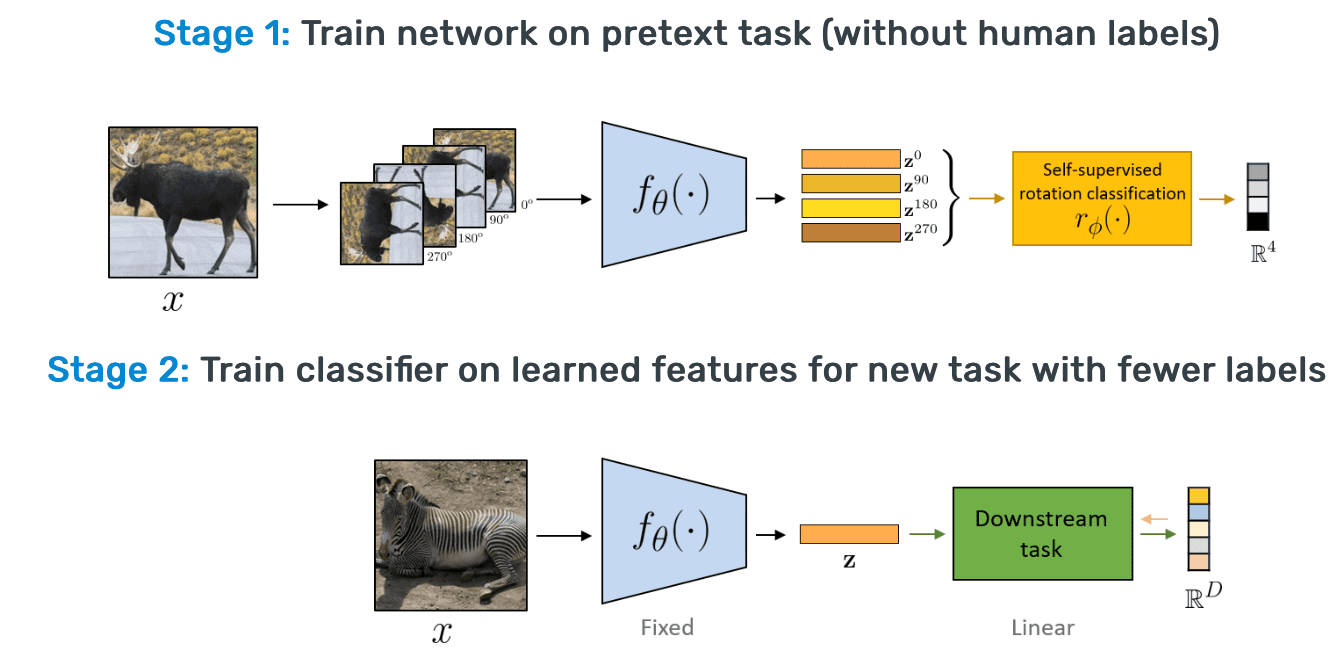
Pada tahap 1 pretext-task, network mempelajari fitur untuk melakukan klasifikasi. Pada tahap kedua, downstream task, encodernya adalah fixed, kemudian beberapa hal yang terkait pretext task dihilangkan seperti linear klasifier z0,-z270 pada gambar diatas. Kemudian digunakan pada downstream dimana kita menggunakan beberapa data, contohnya pada gambar diatas untuk klasifikasi linear. Atau bila kita memiliki tambahan lebih banyak data Downstream task bisa juga digunakan untuk deteksi obyek, segmentasi semantik, dll.
Andrei memberikan contoh analogi pada film Karate Kid. Dimana ada anak (Daniel LaRusso) yang ingin belajar karate ke Mr Miyagi. Namun bukannya diajarin karate tapi malah disuruh kerja macem-macem untuk melatih ototnya seperti pada gambar berikut:

Pre-text dilakukan Daniel dengan melakukan berbagai pekerjaan yang disuruh Mr.Miyagi untuk mengembangkan ototnya. Kemudian dilakukan fine-tuning pada downstream task dengan berlatih karate:

Hal ini yang kita lakukan pada self-supervised, yaitu melakukan training pada pretext-task dengan data yang kita punya, kemudian melakukan finetuning pada downstream task dengan sedikit data berlabel.
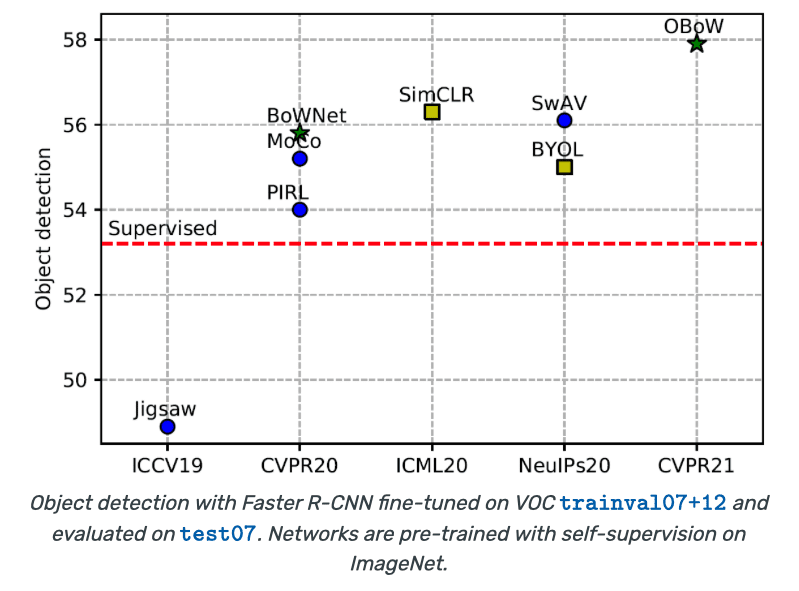
Telah terjadi perkembangan sangat cepat pada self-supervised. Contohnya pada transfer learning untuk deteksi obyek, andrei menampilkan performa metode self-supervised terus meningkat dari tahun ke tahun
Ada banyak pendekatan yang dilakukan peneliti pada self-supervised learning, diantaranya ada rekonstruksi input, generate data, training dengan sinyal berpasangan, menyembunyikan, maupun instance discrimination:

Untuk pengujian metode self-supervised biasanya menggunakan beberapa dataset dan task. Model SoTA saat ini umumnya melakukan pre-training pada ImageNet untuk pretext task dan kemudian melakukan fine-tuning pada dataset/protokol lain. (Goyal dkk, 2019) dan Zhai dkk,2019)
Task pengujian yang digunakan diantarnaya:
- Klasifikasi Linear/probe
- Efficient learning
- Transfer learning
Pengujian pertama metode SSL adalah dengan linear classification. Jadi kita menguji enkoder untuk melakukan klasifikasi linear. Misalnya dengan menambahkan layer FC (full connected, atau dengan linear SVM). Beberapa dataset yang biasanya digunakan adalah ImageNet, Places205, Pascal VOC07 (klasifikasi gambar), COCO14 (klasifikasi gambar, iNat.
Berikut adalah perbandingan performa beberapa metode self-supervised pada ImageNet:
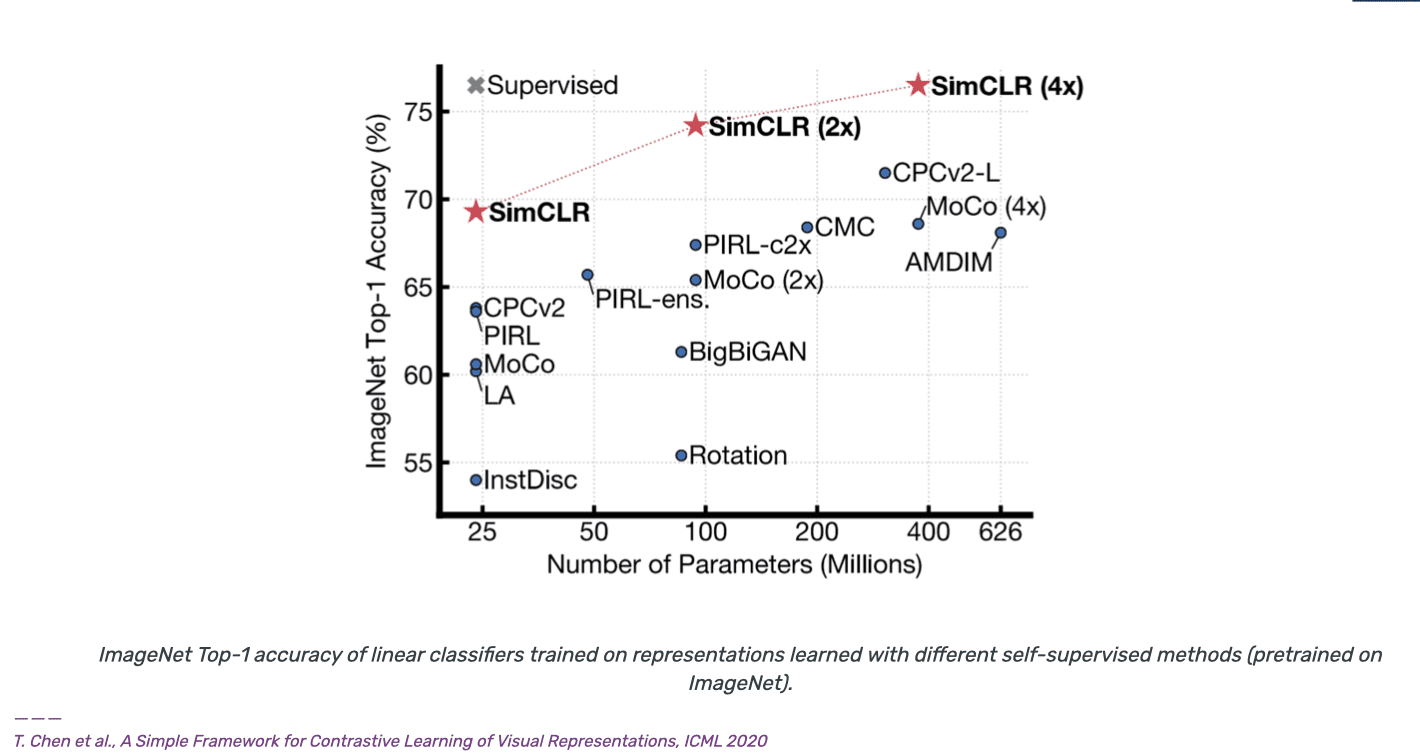
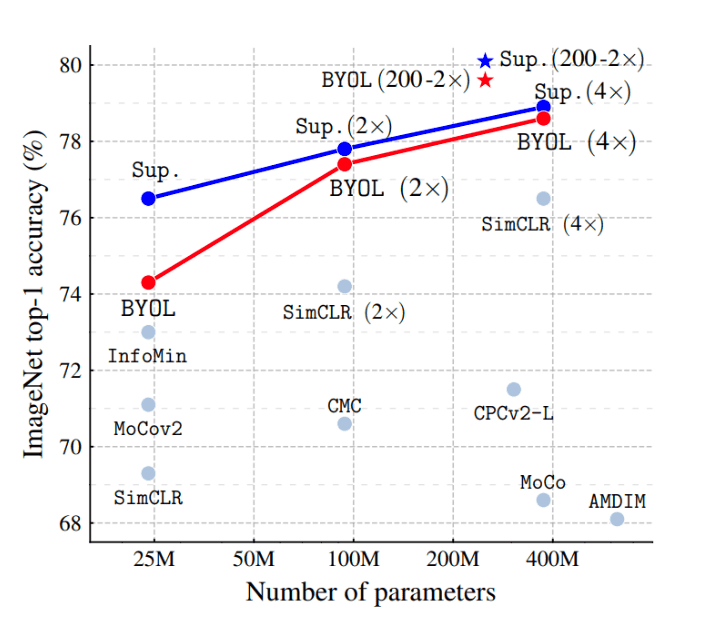
Terlihat self-supervised semakin mendekati performa supervised. Perbandingan lainnya yang lebih baru dilakukan oleh J.B.Grill dkk yang mengajukan metode BYOL
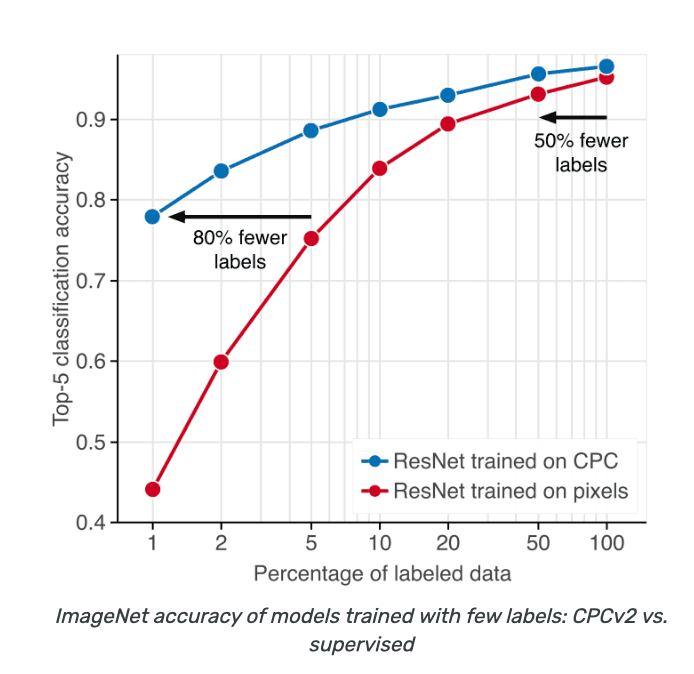
Metode evaluasi kedua adalah Anotation Efficient Classification. Cara ini sering disebut juga semi-supervised learning. Kita melakukan pre-training pada keseluruhan dataset, kemudian fine-tuning pada subset label misalnya 1% data atau 10%. Dataset yang digunakan biasanya ImageNet dan VTAB. Contohnya paper dari O.Henaf dkk “Data-efficient Image Recognition with contrastive predictive coding”, ArXiv 2019. Dia menyimpulkan bahwa supervised network biasanya tidak melakukan generalisasi dengan baik pada data yang sedikit. Sementara self-supervised menghasilkan akurasi yang lebih baik pada data yang sedikit.
Metode evaluasi yang paling populer adalah transfer learning. Model di pretraining dengan augmentasi pada model yang khusus pada task tertentu seperti dekoder untuk segmentasi semantik, RPN untuk deteksi obyek dan kemudian dilakukan fine-tuning secara sebagian atau keseluruhan. Contoh task dan dataset yang digunakan:
- deteksi obyek: VOC07,VOC12,COCO14
- Segmentasi semantik: cityscapes, ADE20K
- Surface Normall Estimation (NYUv2), Visual Navigation (Gibson)
Sampai disini dulu, besok akan saya lanjutkan tentang contrastive learning.
Slidenya bisa dilihat disini:
https://abursuc.github.io/slides//2021-cvpr-ssl/ssl-intro.html#1
Videonya:
Semoga Bermanfaat!