Saya lanjutkan pembahasan kuliah Ishan Misra tentang Self-supervised. Pada tulisan sebelumnya telah dibahas tentang trivial solutions. Yaitu dimana sistem menghasilkan fitur yang sama untuk semua input gambar. Representasi yang dipelajari menjadi tidak dapat digunakan untuk task recognition downstream. Atau bisa dikatakan nilai fungsi encodernya menjadi konstan.
Untuk mengatasi permasalahan trivial solutions ini ada 2 metode self-supervised yang dapat digunakan yaitu:
- Maximize similarity
- Mengurangi redundancy
Untuk maximize similarity beberapa teknik yang bisa digunakan adalah:
- Contrastive Learning (MoCo, PIRL, SimCLR)
- Clustering (DeepCluster, SeLA, SwAV)
- Distillation (BYOL, SimSiam)
Sementara untuk redundancy reduction contohnya adalah Barlow Twins.
Untuk menguji metode SSL diatas, sebuah subset dari dataset Imagenet dataset yang memiliki 1,3 juta gambar dengan lebih dari 1000 kategori tanpa label digunakna untuk melakukan pre-train pada model Resnet-50 yang diinisialisasi secara random. Hasil pre-train akan ditransfer ke downstream task dengan 2 kemungkinan:
- Training sebuah klasifier linear pada fitur yg dibekukan (frozen)
- Finetuning keseluruhan jaringan
Contrastive Learning
Teknik ini digunakan untuk mempelajari fitur umum dari dataset tanpa label dengan mengajari model datapoin mana yang mirip dan yang mana yang berbeda.
Dengan cara ini kita dapat melatih model untuk mempelajari data tanpa membutuhkan anotasi atau lebel (Self-Supervised learning)
Beberapa teknik contrastive learning diantaranya:
- Pretext-Invariant Representation Learning (PIRL)
- SimCLR
- MoCo
Contohnya kita punya sekelompok gambar yang berhubungan (related) dan unraleted contohnya biru dengan biru tua, hijau dengan hijau muda dst

Kemudian gambar-gambar tersebut dimasukan ke jaringan siamese dan dihitung fitur imagenya (embeddingnya). Embedding adalah mapping dari variabel diskret/kategorikal ke vektor kontinu. Neural network embeddings berguna karena dapat mengurangai dimensi dari variabel kategorikal dan dapat merepresentasikan kategori secara berarti pada transformed space.
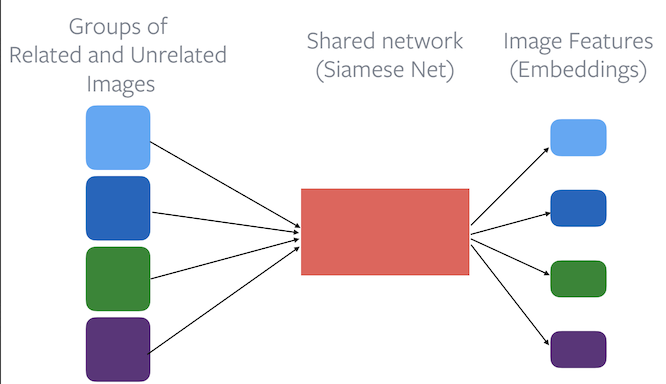
Kemudian dari loss function terlihat bahwa gambar yang berhubungan memiliki nilai loss yang lebih kecil dibandingkan gambar yang tidak berhubungan.

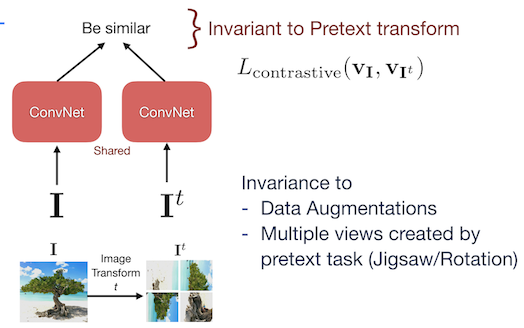
PIRL (Pretext Invariant Representation Learning)
Sebuah Image I dan augmentasinya I^t dimasukan ke jaringan siamese dan dihitung contrastive learning loss sehingga jaringan menjadi invariant terhadap pretext task. Tujuannya adalah untuk mencapai kemiripan yang tinggi pada image dan fitur patch pada gambar yang sama. Dan kemiripan yang rendah pada fitur dari image random lainnya. Pretext task dari PIRL mencoba mencapai invariance terhadap data augmentasi, tidak untuk memprediksi data augmentasi. Image augmentasi dibuat dengan pretext task seperti jigsaw/rotasi.
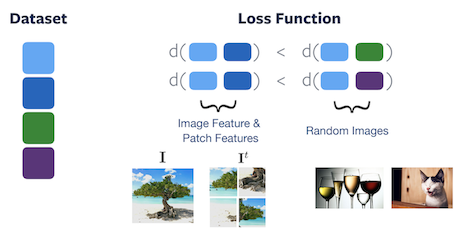
Loss functionnya membandingkan image fetaure dan patch feature. Dimana loss functionnya lebih kecil pada gambar yang sama, dibandingkan loss function pada gambar yang random.
Sampai disini dulu, insyaallah besok akan saya lanjutkan penjelasan tentang metoda PILR
https://towardsdatascience.com/understanding-contrastive-learning-d5b19fd96607
tentang embedding
https://towardsdatascience.com/neural-network-embeddings-explained-4d028e6f0526