Hari ini saya coba lanjutkan pembahasan tentang kuliah Ishan Misra tentang SSL. Pada tulisan sebelumnya telah dibahas tentang PIRL, tentang contrastive learning yang memanfaatkan Pretext untuk membuat model yang invariant. Dari hasil percobaan dia membandingkan performa PIRL dengan model Jigsaw.
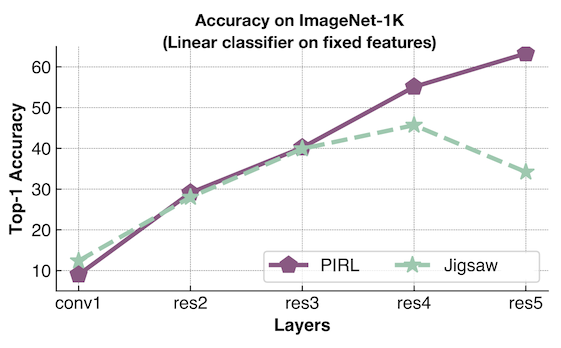
- Sebuah linear classifier digunakan pada setiap layer untuk menghitung akurasi. Satu model ditrain dengan PIRL dan model lain dengan Jigsaw
- Model Jigsaw digunakan untuk prediksi permutasi, sementara PIRL digunakan untuk membuat model yang invarian
- Performa PIRL terus meningkat, yang menunjukan fitur yang semakin mendekati downstream klasifikasi task.
- Model Jigsaw mencoba untuk mempertahankan informasi pretext, performa meningkat dan kemudian menurun pada layer akhir, namun tidak memiliki performa bagus pada transfer task
Ada banyak metode yang digunakan untuk menentukan mana sampel yang related (positif) dan unrelated (negatif).
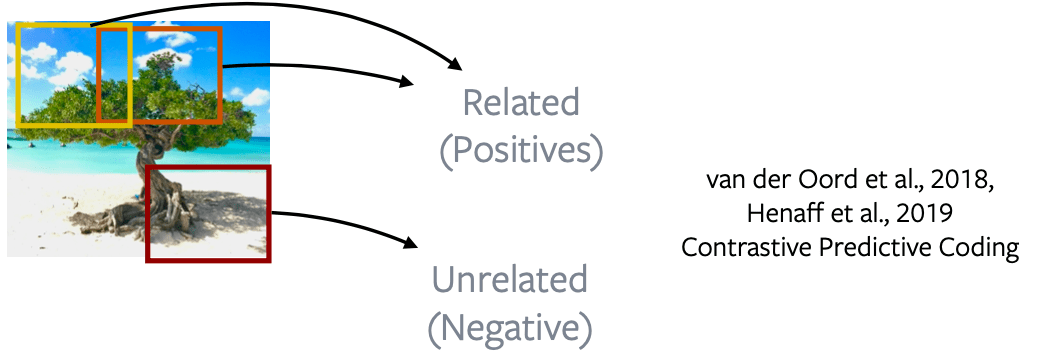
- Potongan dari sebuah gambar (Crops of an image): model Contrastive Predictive Coding (CPC) based menggunakan patch dari sebuah gambar yang berdekatan sebagai positives (related) dan patch yang berjauhan sebagai negatives (unrelated).
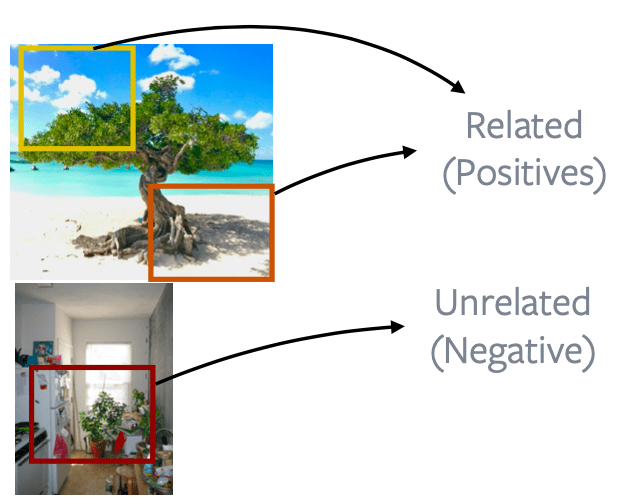
- Potongan dari gambar yang berbeda (Crops across image): Patch dari gambar yang sama dianggap related dan patch dari 2 gambar berbeda adalah unrelated. Model ini digunakan pada MoCo dan SimCLR
- Videos: Frame yang berurutan adalah related, dan yang tidak berurutan adalah unrelated

- Multimodal – Video and Audio: urutan Video dan file suara dari sumber (kejadian) yang sama disebut related. Sementara urutan Video dari satu video dengan audio dari sumber berbeda adalah unrelated.

- Video Object Tracking: pada metode ini sebuah obyek dilacak pada beberapa frame berbeda pada sebuah video. Patch dari video yang sama adalah related. Sementara patch dari video berbeda adalah unrelated.
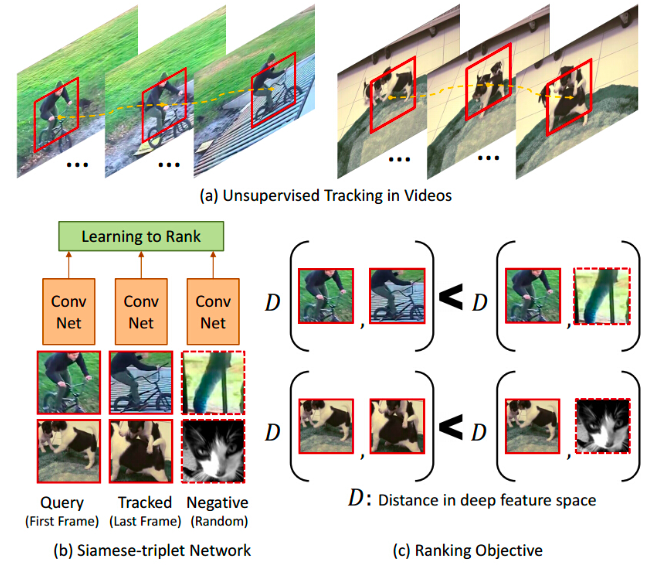
Setelah mengetahui konsep tentang related dan unrelated ini, kita dapat membangun model yang mampu mempelajari fitur dengan contrastive learning.
Karakteristik (property) apa pada contrastive learning yang dapat mencegah trivial solution?
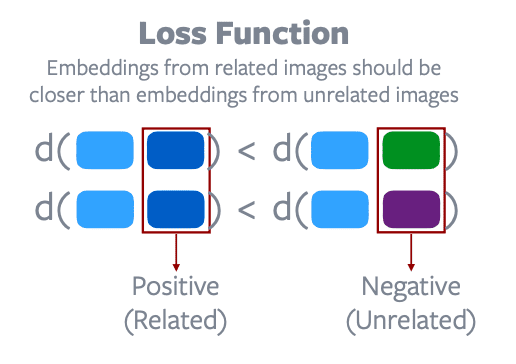
Tujuan dari contrastive learning adalah untuk mencegah solusi trivial. Caranya dengan memastikan distance antara pasangan embedding positiv (yang related) lebih kecil daripada distance antara pasangan embedding negatif (yang unrelated). Solusi trivial terjadi ketika distancenya adalah konstan untuk semua pasangan embedding. Contrastive learning melakukan minimisasi terhadap loss function. Dari hasil penelitian pasangan negatif yang baik (good negatif) adalah bagian penting dari contrastive learning. Bahkan ada yang meneliti bagaimana mendapatkan pasangan negatif yang baik untuk meningkatkan performa.
Sampai disini dulu, besok akan saya lanjutkan dengan metoda SimCLR. Semoga Bermanfaat!
Materinya bisa dilihat pada link berikut:
https://atcold.github.io/NYU-DLSP21/en/week10/10-1/
slidenya ada disini:
https://drive.google.com/file/d/1BQlWMVesOcioW69RCKWCjp6280Q42W9q/edit
Videonya: