Tulisan ini adalah bagian kedua bahasan tentang Self Supervised Learning (SSL) dari blognya Yann Lecun dan Ishan Misra, bagian pertama bisa dilihat disini.
SSL mendapatkan supervisory signal (label output yang diinginkan) dari dataset, seringkali memanfaatkan struktur yang ditemukan pada data. Teknik SSL yang umum adalah untuk memprediksi bagian yang tidak teramati atau tersembunyi dari input dari bagian input yang diamati atau tidak tersembunyi. Contohnya pada NLP, kita bisa menyembunyikan bagian dari sebuah kalimat dan melakukan prediksi kata apa yang tersembunyi dari kata-kata yang ada. Dari sebuah fram video, kita juga dapat memprediksi frame sebelumnya maupun frame berikutnya. Karena SSL menggunakan struktur data itu sendiri, maka sinyal yang digunakan bisa beragam dari berbagai modal (misalnya video dan audio) dan dari berbagai dataset besar, tanpa mengandalkan label.
Karena supervisory signal memberi informasi ke SSL, istilah “Self-supervised learning” lebih cocok dibandingkan “unsupervised learning”. Unsupervised learning menunjukan proses learning tidak membutuhkan supervisi dari orang. SSL berbeda dengan unsupervised, karena membutuhkan feedback sinyal yang jauh lebih banyak dibandingkan supervised learning dan reinforcement learning.
SSL pada NLP
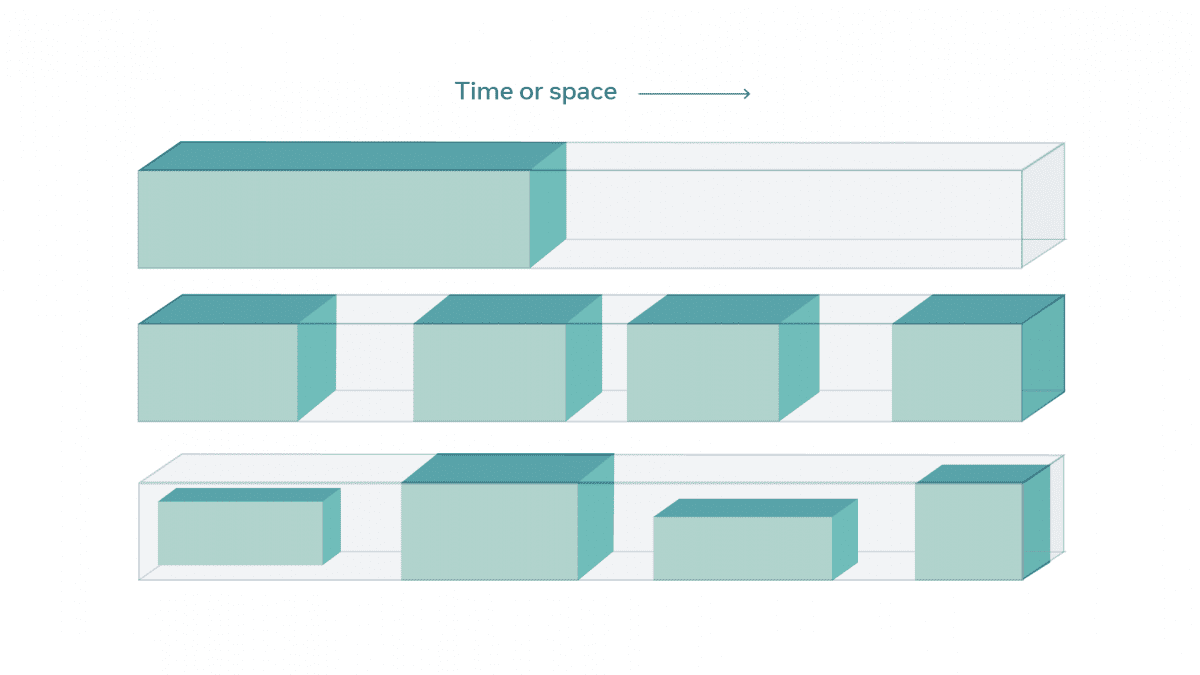
SSL telah berhasil digunakan pada NLP (natural language processing), dengan melatih model seperti BERT, RoBERTa, XLM-R, dll pada dataset besar yang belum memiliki label, kemudian menggunakan model ini pada task downstream. Model-model ini dilakukan pretraining pada fase self-supervised dan di tuning atau disesuaikan untuk task tertentu, seperti klasifikasi topik dari sebuah teks. Pada saat pretraining self-supervised, sistem ditunjukan sebuah teks pendek (biasanya sekitar 1000 kata) dimana beberapa kata telah ditutupi (masked) atau diganti. Sistem kemudian ditrain untuk melakukan prediksi kata yang telah ditutupi atau diganti. Sistem belajar untuk mencari representasi arti dari kata sehingga dapat mencari kata yang cocok, atau yang sesuai dengan konteks.
Mengisi bagian input yang hilang adalah task standar pada pretraining SSL. Untuk melengkapi sebuah kalimat seperti ” Seekor …… mengejar …. di savana (padang rumput)” sistem harus belajar bahwa singa maupun cheetah dapat mengejar kijang atau rusa, tapi kucing mengejar tikus di dapur, tidak di savana. Selama training, sistem belajar untuk mencari representasi arti dari kata-kata, peran sintatik dari kata-kata dan maksud dari seluruh teks.
Namun teknik ini tidak mudah diterapkan pada domain baru seperti komputer vision. Walaupun hasil awal cukup menjanjikan, SSL belum menghasilkan performa pada komputer vision seperti yang kita lihat pada NLP.
Alasan utamanya adalah lebih sulit untuk merepresentasikan ketidakpastian pada prediksi gambar dibandingkan pada kata-kata. Ketika kata yang hilang tidak bisa diprediksi secara tepat (apakah singa atau cheetah), sistem dapat menggunakan skor atau probabilitas untuk semua kemungkinan kata-kata dalam kosa kata: skor tinggi untuk singa, cheetah dan predator lainnya, dan memberikan nilai rendah pada kata-kata lain pada kosakata.
Melakukan training model pada skala ini membutuhkan sebuah arsitektur model yang efisien dari segi runtime dan memori, tanpa mengorbankan akurasi.
Untungnya, inovasi baru dari FAIR tentang desain arsitektur menghasilkan sebuah model keluarga baru yang disebut RegNets, yang sangat sesuai dengan kebutuhan ini. Model RegNet adalah ConvNet yang mampu meningkatkan skala data hingga miliaran atau bahkan triliunan parameter, dan dapat dioptimasi agar sesuai dengan runtime dan batasan memori yang berbeda.
Namun, kita belum tahu cara merepresentasikan ketidakpastian secara efisien ketika memprediksi frame yang hilang dalam video atau patch yang hilang pada gambar. Kami tidak dapat membuat daftar semua kemungkinan frame video dan mengaitkan skor ke masing-masing frame, karena jumlahnya tak terbatas. Sementara masalah ini telah membatasi peningkatan kinerja dari SSL dalam vision, teknik-teknik baru SSL seperti SwAV mulai mengalahkan rekor akurasi dalam tugas-tugas visi. Ini paling baik ditunjukkan oleh sistem SEER yang menggunakan jaringan konvolusi besar yang dilatih dengan miliaran data.
Sampai disini dulu, besok akan saya lanjutkan tentang pemodelan ketidak pastian, Semoga bermanfaat!