Saya lagi baca tulisan Lilian Weng tentang Self-Supervised Learning. Berikut beberapa rangkuman dari tulisan tersebut.
Bila kita memliki data yang banyak dan berlabel, supervised learning dapat menyelesaikan berbagai task dengan baik. Namun melakukan labeling data secara manual sangat mahal, contohnya Imagenet. Padahal ada banyak sekali data yang tersedia dan belum memiliki label, contohnya teks, dan jutaan gambar di itnernet. Sementara itu teknik unsupervised learning tidak mudah dan tidak efisien. Proses labeling seringkali dilakukan oleh manusia secara manual.
Bagaimana bila kita bisa mendapatkan label otomatis dari data? Dan melakukan training dari dataset yang tidak memiliki label dengan cara supervised? Kita dapat melakukan ini dengan mengubah bentuk task supervised learning hanya untuk memprediksi sebagian informasi menggunakan info yang ada. Dengan cara ini, semua informasi yang dibutuhkan baik input maupun label telah tersedia. Teknik ini dinamakan Self-supervised learning.
Ide ini telah banyak digunakan pada nlp. Default task untuk model bahasa adalah mempelajari kata berikutnya berdasarkan urutan sebelumnya. BERT menambahkan dua task tambahan mengandalkan pada label yang dibuat atau digenerate sendiri.
Link berikut ini adalah daftar beberapa paper tentang self-supervised learning. Tulisan ini gak membahas tentang language modeling atau generative modeling.
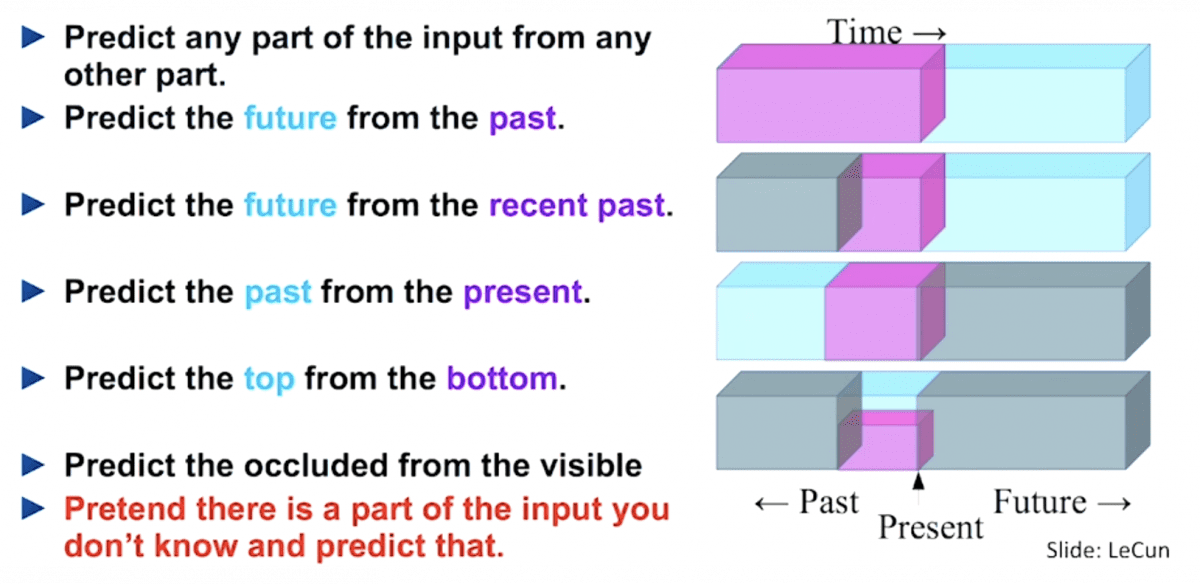
Kenapa SSL?
Self-supervised learning (SSL) memungkinkan kita untuk mengeksploitasi berbagai label yang ada pada data secara gratis. Alasannya digunakannya SSL adalah karena mendapatkan label adalah mahal, sementara data tanpa label tersedia banyak. Untuk menggunakan data ini, salah satu caranya adalah menentukan “learning objective” yang sesuai untuk mendapatkan supervision dari data tersebut.
Self-supervised task, dinamakan juga pretext task, membawa ke fungsi loss supervised. Namun performa task ini belum baik. Yang diharapkan adalah representasi intermediate dapat memberikan semantik atau struktur yang berarti dan dapat digunakan untuk berbagai downstream task.
Contohnya kita dapat melakukan rotasi gambar secara random dan melatih sebuah model untuk memprediksi bagaimana rotasi gambar tersebut. Prediksi rotasi dirancang sehingga akurasi tidak penting, seperti kita memperlakukan task tambahan, Tapi kita mengharapkan model untuk dapat mempelajari variabel laten dengan kualitas tinggi untuk task sebenarnya, seperti untuk klasifikasi pengenalan objek dengan jumlah label sedikit.
Secara umum semua model generatif dapat dimasukan sebagai self-supervised, tapi dengan tujuan yang berbeda: Model generativ fokus pada membuat gambar yang berbeda dan realistik, sementara self-supervised lebih peduli terhadap menghasilkan fitur yang baik yang dapat digunakan untuk berbagai task. Tentang model generative bisa dipelajari pada tulisan berikut. Sampai disini dulu, besok akan saya lanjutkan tentang representasi image, insyaAllah.
Referensi:
https://lilianweng.github.io/lil-log/2019/11/10/self-supervised-learning.html