Pada tulisan sebontihelumnya telah dibhas tentang Bayesian Network, kemudian tentang structured learning menggunakan algoritma Chow-Liu. Berikut ini adalah contoh pencarian tree terbaik menggunakna algoritma chow-liu dengaan greedy algoritma untuk mencari max-spanning tree. Misalnya diperoleh dari perhitungan chow lie diperoleh nilai bobot antar edge sebagai berikut:
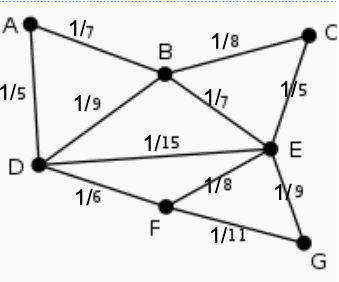
Pada gambar diatas terdapat 7 variabel, A-G. Harusnya memang fully connected, tapi disederhanakan seperti gambar diatas. Kemudian dicari nilai spanning tree maksimal, yaitu dicari busur dengan nilai bobot terbesar. Pada kasus ini yang terbesar adalah 1/5 yaitu AD, CE.
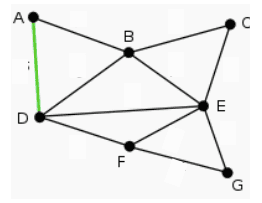
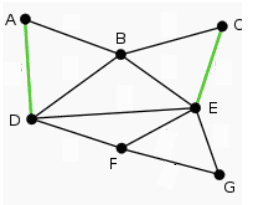
Kemudian yang terbesar kedua adalah 1/6 DF. Perlu diingat bahwa tidak ada yang membentuk siklus. Bobot ini diperoleh dari perhitungan mutual information antara titik.
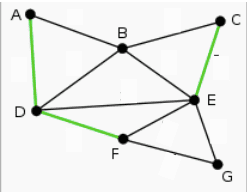
Kemudian ada 1/7 yaitu AB, BE. Kemudian ada 1/8 yaitu BC. Namun ternyata BC membentuk siklus, sehingga tidak digunakan. Kemudian ada juga FE, yang membentuk siklus. Kemudian ada 1/9 EG, tidak membentuk siklus, DB membentuk siklus.
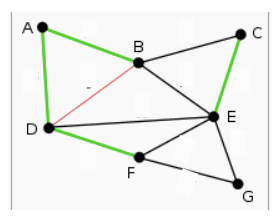
Kemudiah ada 1/15 DE yang membentuk siklus.
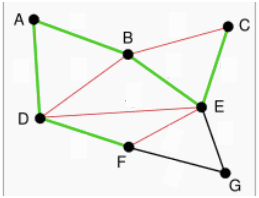
Sehingga pada gambar dibawah ini didapat spanning tree dengan garis hijau. Untuk garis merah membentuk siklus, sehingga tidak digunakan.
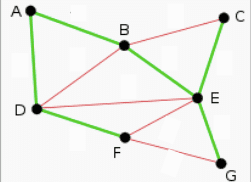
Spanning tree nya bermacam2, bisa dimulai dari B dari E, atau D dll. Pada tahapan ini, graphnya belum berarah.
Untuk penelitian terbaru tentang structure learning contohnya bisa dilihat paper berikut:
Di NLP bayesian network tidak banyak digunakan. Contoh implementasi bayesian network ini adalah di Kesehatan, sosial science, ekonomi dll. Untuk social science sekarang datanya biasanya didapat dari sosial media. Hanya saja keterbatasan teknik bayesian network adalah hubungan antar variabel yang independen. Selain itu DAG tidak selalu pohon bentuknya. Pohon itu rootnya selalu 1.
Beberapa catatan tentang bayes net:
- Representasi: Bayesnet merepresentasikan join distribution sebagai DAG dan conditional distribution;
- Representasi: D-separation bisa digunakan untuk menentukan apakah simpul conditional independence atau tidak. Bisa terlihat secara visual
- Inference: bisa dihitung langsung, dengan menghitung jumlah semua kemungkinan variabel berdasarkan joint probability distriutiobbya kemungkinannya
- Inference: bisa menggunakan metode approximate seperti monte carlo, digenerate dataset berdasarkan CPD nya.
- Learning: mudah bila datanya lengkap dengan MLE, MAP dll
- Learning: EM bila datanya partly observed
- Learning: membangun struktur tree misalnya dengan chow-liu
Semoga Bermanfaat!
Referensi:
Mitchell, Tom. “Machine learning.” (1997): 870-877.