Saya lanjutkan pembahasan tentang kuliah Self-supervised Learning pada Vision dari Ishan Misra. Pada materi sebelumnya telah dibahas beberapa teknik untuk menangani solusi trivial yaitu dengan memaksimalkan similarity, diantaranya contrastive learning, clustering dan distillation. Selanjutnya akan dibahas tentang teknik lainnya yaitu redundancy reduction. Khususnya Barlow twins: ssl via barlow twins.
Karena otak kita memiliki keterbatasan jumlah state, kita tidak bisa memasukan banyak jumlah neuron, dan ada keterbatasan energi, dimana kita tidak bisa memberi power tak terbatas pada otak. Ini adalah 2 batasan dari neuron. Sehingga komunikasi antara neuron harus dibuat efektif.
Menurut Barlow, spiking code ini melakukan reduksi (pengurangan) redundansi antara neuron. Contohnya bila kita memiliki 10 neuron, kita tidak ingin semuanya mengirim informasi yang sama. Tapi mungkin dibagi, sebagian lebih fokus pada konsep tertentu, yang lain fokus pada konsep lain.
Bagaimana proses reduksi rendundancy nya?
Bila kita memiliki N neuron yang menghasilkan representasi dengan fitur dengan N dimensi. Misalnya chanel pada convnet, dengan 2048 dimensi fitur. Setiap neuron harus memenuhi syarat berikut:
- Invariance-teknik augmentasi apapun yang digunakan spike atau representasi yang dihasilkan neuron harus invariance terhadap input, terhadap augmentasi
- Independen terhadap neuron lainnya: karena kita tidak ingin selama neuron memiliki informasi yang sama, atau dekorelasi antara mereka. Untuk mengurangi redundansi
Sehingga bisa dikatakan, pada persamaan dibawah ini kita memiliki fθ (I) yang menghasilkan representasi N dimensi dengan [i] adalah indeks representasi dari vektor. [i] dan [j] merepresentasi neuron yang berbeda. fθ (I) pada neuron yang sama harus sama pada augmentasi apapun atau sesuai dengan syarat invariance.
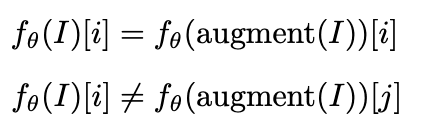
Kemudian pada persamaan kedua kita ingin mereka independen, sehingga tidak menghasilkan output yang sama. Pada neuron [i] harus menghasilkan representasi yang sama pada gambar asli dan gambar yang yang sudah teraugmentasi. Sementara pada neuron [i] dan neuron [j] harus berbeda. Syarat kedua ini kita ingin mencegah timbulnya solusi trivial, dimana semua neuron menghasilkan output yang sama.
Kita memiliki 2 jaringan, yang menghitung versi distorted atau versi augmentasi dari sebuah input image, dimasukan ke encoder, sehingga kita mendapatkan dua representasi ZA dan ZB adalah representasi dari sebuah gambar yang sama dari dua teknik augmentasi yang berbeda.
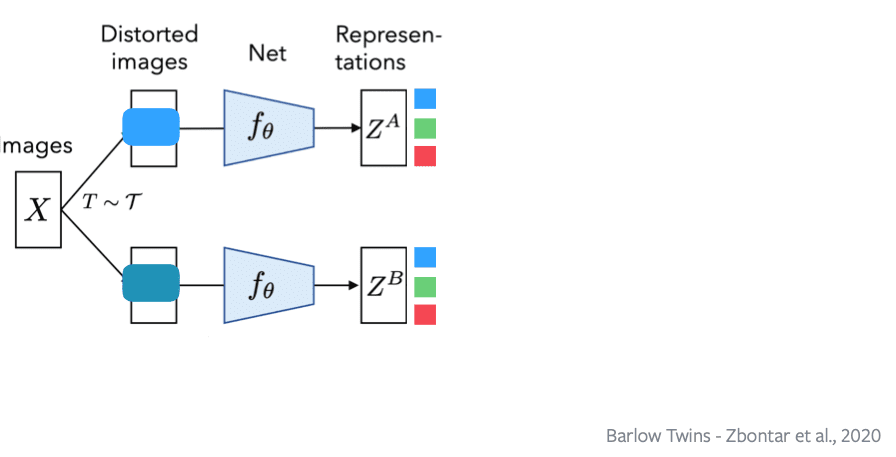
Kemudian kita memiliki 3 neuron biru, hijau dan merah. Properti pertama (invariance) contohnya neuron biru harus menghasilkan representasi yang sama pada ZA dan ZB, begitu juga dengan neuron hijau dan merah.
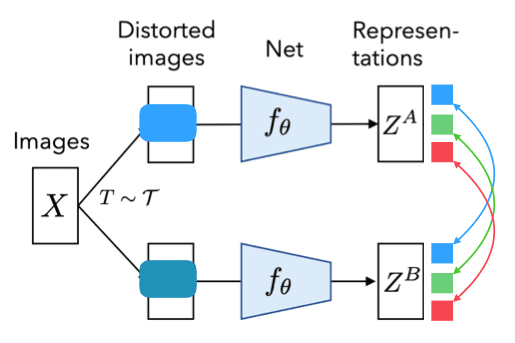
Sehingga kita memiliki invariance, dimana semua neuron menghasilkan output yang sama.
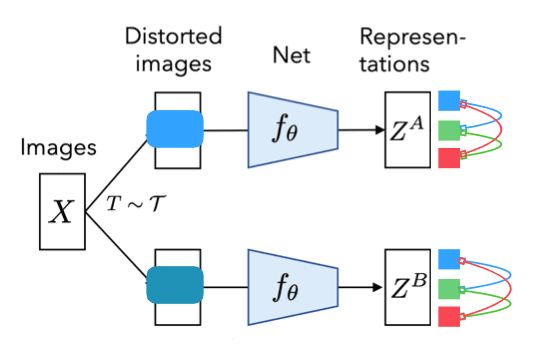
Kemudian ada kondisi yang kedua (reduksi redundansi) pada gambar berikut dimana semua neuron menghasilkan output yang berbeda, atau kita tidak mau neuron merepresentasikan hal yang sama. Ini untuk mencegah terjadinya kolaps.
Implementasinya adalah kita menghitung cross-corelasi antara fitur matriks. Bila kita memiliki matriks fitur dengan N dimensi, B x D dimana B adalah ukuran batch dan D adalah dimensi dari fitur. Kita akan menghitung D x B atau fitur dimensi dikali fitur matriks atau cross corelation dari D atau outer product.
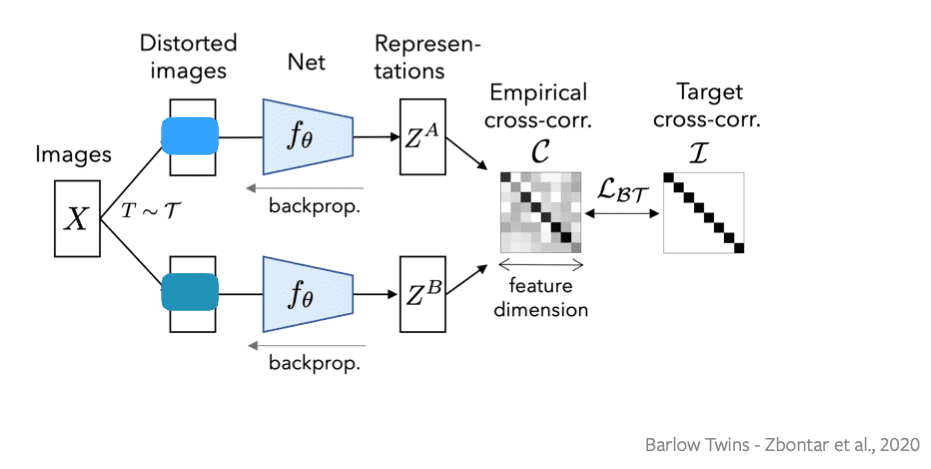
Sehingga setelah kita memiliki fitur matriks dan cross corelation matriks, supaya memenuhi dua syarat diatas, kita ingin matriks ini menjadi sama atau semirip mungkin dengan matriks identitas. Matriks identitas adalah semua neuron yang ada di diagonal. Neuron sama dari berbagai augmentasi data menghasilkan output yang sama. Dan neuron yang berbeda harus menghasilkan output yang berbeda.
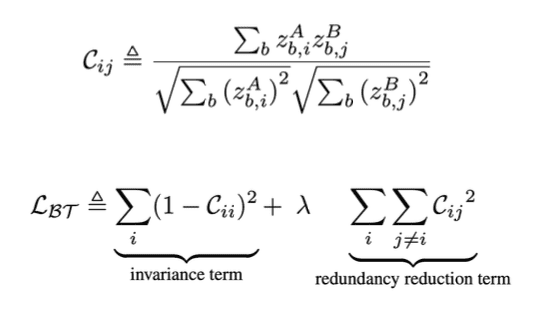
Lbt adalah loss, dan cross corelation yang kita prediksi dari fitur harus sama dengan matriks identitas. Setelah kita meminimalkan loss, kita lakukan backpropagasi gradientnya dan mengupdate nilainya.
Pada proses ini kita tidak ada menambahkan operasi proses asimetri apapun seperti pada konsep student teacher (SimSiam).
Cij dapat dihitung sebagai cross corelation antara ZA dan ZB, sementara loss dihitung dari cross corelation dibuat sama dengan matriks identitas, dan bisa kita bagi jadi dua. Yaitu nilai identitas yaitu bagian invariance, kemudian bagian kedua adalah bagian redundancy reduction.
Parameter dari lambda adalah menghitung tradeoff, contohnya kita punya matriks N x N. Maka hanya ada N entri diagonal, atau pada bagian pertama (invariance) hanya punya N nilai didalamnya. Sementara pada bagian kedua (identitas) ada N^2-n nilai. Lambda mencoba untuk menyeimbangkan kontribusi dari kedua nilai ini. Karena kita memiliki lebih banyak redundancy reduction dari pada invariance.
Distorsi dari image adalah random, setiap kita melakukan forward pass maka kita menghitung distori random.
Pada kasus kita memiliki representasi konstan dimana neuron menghasilkan output yang sama, kita tidak dapat meminimalkan loss function sehingga kita menghasilkan solusi trivial. Ada satu kasus solusi trivial lainnya dimana neuron menghasilkan output berbeda (decorelated) tapi ada kemiripan antara gambar. Untuk mengatasinya kita bisa meletakan ZA dan ZB ditengah (Centered) sebelum menghitung cross-correlation, maksudnya seperti melakukan operasi batch norm. ZA dibagi dengan rata-ratanya dan dibagi dengan deviasi standarnya.
Bagaimana teknik ini mencegah solusi trivial ? Karena bila kita menghasilkan output yang sama dari berbagai gambar, dengan melakukan centered maka kita akan matriks nol.
Jadi kita memiliki dua cara untuk mencegah solusi trivial, pertama dengan menggunakan syarat invariance dan redundansi reduction, kedua dengan melakukan operasi centered. Sampai disini dulu, besok insyallah saya lanjutkan.
Materinya bisa dilihat disini:
https://atcold.github.io/NYU-DLSP21/en/week10/10-2/
slidenya ada disini:
https://drive.google.com/file/d/1BQlWMVesOcioW69RCKWCjp6280Q42W9q/edit
Videonya:
Satu tanggapan untuk “Barlow Twins – Ishan”
Great post, thanks for sharing.