Saya lanjutkan pembahasan tentang paper Self-Supervised Visual Feature Learning with Deep Neural Network: A Survey dari Longlong Jing dan Yingli Tian. Pada tulisan sebelumnya telah dibahas tentang macam-macam teknik learning feature pada image, diantaranya dengan metode Image Generation dengan Colorization. Sekarang kita lanjutkan tentang metode context based image feature learning.
Pretext task berbasis konteks menggunakan fitur konteks dari image seperti context similarity, spatial structure, dan temporal structure sebagai supervision signal. Fitur-fitur ini dipelajari oleh jaringan ConvNet melalui proses penyelesaian pretext tasks.
Ada dua macam teknik yang bisa digunakan yaitu: Learning dengan context similarity dan learning dengan spacial context structure.
Learning with context similarity
Clustering adalah metode untuk mengelompokan data-data yang memiliki kemiripan dalam cluster yang sama. Teknik ini banyak digunakan pada machine learning, image processing, computer graphics, dll.
Pada self-supervised scenario, metode clustering methods digunakan sebagai alat untuk mengkluster gambar. Contohnya metode untuk mengklaster gambar berdasarkan fitur yang dirancang manual seperti HOG, SIFT, atau Fisher Vector. Hasil dari klastering adalah didapatkannya beberapa klaster. Gambar pada satu klaster memiliki jarak yang lebih kecil pada feature space. Sementara gambar pada klaster berbeda memiliki jarak yang lebih besar. Semakin kecil jarak pada feature space, maka semakin mirip gambar tersebut dalam RGB space.
Kemudian jaringan ConvNet dapat dilatih untuk melakukan klasifikasi data berdasarkan klaster yang ada. Untuk melakukan klasifikasi, Convnet mempelajari invariance pada satu kelas dan variance antara kelas berbeda. Inilah yang disebut ConvNet mempelajari makna semantik dari gambar. Contohnya adalah DeepCluster, bisa dilihat pada gambar berikut.
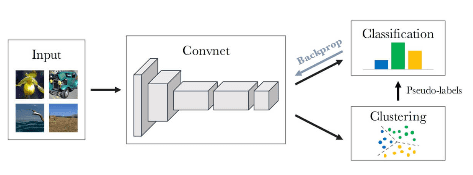
DeepCluster melakukan klastering gambar secara iterativ dengan Kmeans dan menggunakan task ini sebagai supervisi untuk mengupdate weight dari jaringan. Metode ini masih menjadi sistem state-of-the-art dari self-supervised image representation learning.
Learning with Spatial context structure
Gambar memiliki informasi dengan konteks spatial seperti posisi relatif terhadap bagian patch lain dari gambar. Informasi ini dapat digunakan untuk pretext task pada self- supervised learning. Pretext task dapat melakukan prediksi posisi relatif dua patch pada sebuah gambar yang sama. Atau mengenali urutan dari urutan patch yang diacak pada gambar yang sama.
Konteks dari keseluruhan gambar dapat digunakan menjadi sinyal supervisi untuk mengenali sudut rotasi dari gambar. Untuk menyelesaikan pretext task ini ConvNet harus mempelajari informasi konteks spatial, seperti bentuk obyek dan posisi relatif dari bagian berbeda sebuah gambar.
Metode yang diusulkan Doersch dkk adalah salah satu pioner penggunakan konteks spatial untuk self-supervised visual feature learning. Pasangan acak dari patch gambar diekstrak dari setiap gambar, kemudian ConvNet ditraining untuk mengenali posisi relatif dari obyek pada gambar. Selain itu dipelajari juga hubungan antara bagian2 berbeda pada obyek.
Untuk menghindari solusi trivial digunakan edge pada patch. Augmentasi data banyak dibutuhkan pada proses training. Metode lainnya adalah spatial puzzles. Noroozi dkk berusaha menyelasikan image Jigsaw puzzle dengan ConvNet. Contohnya pada gambar dibawah (a) adalah gambar dengan 9 image patches. Gambar (b) adalah contoh shuffled image patches, dan gambar(c) adalah urutan yang benar dari 9 patches.

Gambar patch yang diacak dimasukan ke jaringan, dan dikenali lokasi spatial yang benar dengan mempelajari spatial context dari gambar seperti warna, struktur dan informasi semantik tingkat tinggi.
Untuk gambar dengan 9 patch, terdapat sebanyak 362. 880 kemungkinan, atau permutasi(9!). Untuk menyederhanakan digunakan hamming distance untuk memilih hanya subset dari permutasi yang memiliki nilai hamming distance tinggi.
Prinsip pada puzzel task ini adalah merancang task yang tidak terlalu sulit dan terlalu mudah untuk diselesaikan oleh jaringan. Bila terlalu sulit maka jaringan sulit untuk konverfen. Bila terlalu mudah maka dapat terjadi solusi trivial. Sehingga reduksi pada search space digunakan untuk mengurangi kesulitan dari task.
Sampai disini dulu, besok insyaAllah saya lanjutkan dengan metode free semantic label-based image feature learning.
Papernya bisa dilihat pada link berikut :
https://arxiv.org/abs/1902.06162
Semoga bermanfaat!