Saya lanjutkan bahasan tentang Decision Tree . Salah satu kelemahan Decision Tree (DT) adalah Overfitting. Contoh overfitting misalnya pada kasus ada noise (data salah), kemudian dibentuk pohon yang mengakomodasi data ini. Pohon ini cenderung membesar. Jadi tree ini dikatakan terlalu ditune untuk mengakomodasi data training tertentu.
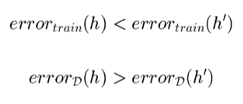
error train (h) adalah error tree pada saat training. Sementara error train (h’) error training pada hipotesis lain. Error pada train misalnya terjadi karena datanya sangat besar dan kompleks. Error d(h) adalah true error (eror pada tes data), misalnya error pada data yang besar sekali.
Untuk mencegah overfitting:
- Berhenti ketika split data tidak signifikan secara statistik
- Atau terus menumbuhkan pohon kemudian melakukan post pruning, atau dipotong daunnya secara selektif hingga performa tes validasi membaik.
Bagaimana memilih pohon yang baik?
- Mengukur performa data training
- Mengukur performa menggunakan dataset validasi yang terpisah (banyak digunakan)
- Menggunakan MDL (minimum disruption length) atau minimize
size(tree) + size (misclassification(tree))
Pada metode 2, kita bisa membagi dataset jadi 3, data training, tes dan validasi. Pada saat training diukur performanya secara bertahap, mulai dari 1 simpul 2 simpul dan seterusnya. Pada saat tree mulai terbentuk, kemudian dilakukan pengujian dengan data validasi. Disini diperhatikan grafik perform tree. Biasanya performanya akan meningkat ketika simpul2nya ditambah. Namun akan ada satu titik dimana performanya akan menurut. Nah pada saat inilah terjadi overfitting, dan sebaiknya pada saat ini dihentikan penambahan simpulnya.
Sementara pada teknik MDL diukur ukuran tree dan ukuran kesalahan klasifikasinya (misclassification). Pada MDL ini dicari ukuran tree yang kecil namun kesalahannya juga kecil. Titik ini yang disebut optimal. Karena bisa saja ukuran tree nya membesar dan error nya mengecil.
Teknik lainnya adalah Pruning (reduced-error pruning). Disini pohon ditumbuhkan dulu sampai penuh. Teknik ini menggunakan data validasi juga. Kemudian dilakukan pemotongan simpul, kemudian diuji performanya dengan data validasi. Bila performanya meningkat, kemudian lakukan lagi pemotongan simpul berikutnya dan diuji lagi performanya dengan data validasi. Proses ini dilakukan berulang-ulang hingga didapat nilai performa yang terbaik dengan tree terkecil. Metode pruning ini bisa meningkatkan performa pada data tes.
Bagaimana bila datanya sedikit? bisa digunakan juga metode cross-validation.
Sampai disini dulu. Semoga Bermanfaat!