Hari ini saya belajar tentang Decision Tree (DT). DT ini bisa dibilang salah satu algoritma klasik pada machine learning. DT ini memiliki masalah overfitting. Yaitu pada saat training performanya bagus, namun pada saat test performanya jelek. Hal ini bisa jadi karena dia kehilangan kemampuan melakukan generalisasi, karena sangat ditune pada training datanya.
Secara keseluruhan Machine learning adalah studi terhadap algoritma untuk meningkatkan performa P, pada beberapa task T berdasarkan pengalaman E: (P,T,E).
Untuk mendapatkan fungsi yang akan kita pelajari, kita memiliki :
- sekumpulan instance X (ruang input/dataset),
- ada fungsi target yang kita tidak ketahui f:X–>Y
- kumpulan hipotesis H={ h | h : X –> Y} (calon solusi)
Input sistem adalah pasangan
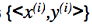
dari tipe fungsi target f
Outputnya adalah hipotesis h yang merupakan bagian dari H, yang paling mendekati fungsi target f
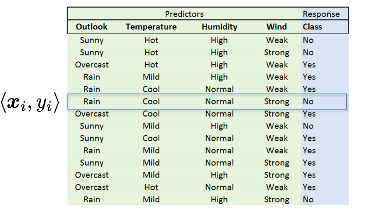
Contohnya pada gambar diatas kolom-kolomnya (outlook, temperature, humidity dan wind) adalah fitur dari Xi. Baris-barisnya menunjukan instance label <xi, yi>. Label kelasnya pada tabel ini adalah kolom berwarna biru yang menunjukan yes dan no.
Contoh decision tree dari tabel diatas F:<Outlook, Humidity, Wind, Temp> –> play tennis
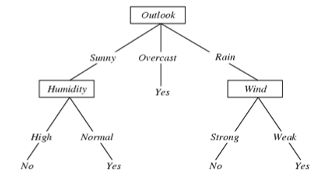
Setiap internal node menyatakan atribut tes Xi. Node pada gambar diatas berbentuk kotak, yaitu outlook, Humidity, dan wind.
Setiap cabang dari sebuah node menunjukan nilai dari sebuah node Xi. Contoh cabang pada gambar diatas ada sunny, overcast dan rain.
Setiap daun (leaf node) adalah hasil prediksinya (yes dan no) atau bisa disebut juga keputusan.
Ada banyak kemungkinan pohon, namun yang dicari adalah yang optimal, sependek mungkin. Kalau ada atribut yang tidak relevan, bisa saja dia hilang dari pohon DT.
Pohon ini kemudian digunakan untuk prediksi kelas dari sebuah input. Misalnya kita punya input berikut: <outlook=sunny, temperature=hot, humidity=high, wind=weak> . Bila kita masukan input tersebut ke pohon, maka akan mengikuti jalur keputusan outlook=sunny, humidity= high berarti keputusannya adalah playtennis=no. Dari contoh input ini temperature dan wind menjadi atribut yang tidak relevan dan tidak digunakan.
Bila datanya berupa numerik atau kontinyu, digunakan threshold atau ambang batas sebagai fitur. Misalnya untuk humidity high dan normal bisa diganti threshold >75% dan <75%. Atau bisa juga dikatakan data kontinu diubah menjadi data kategorikal. Sampai disini dulu. InsyaAllah besok akan saya lanjutkan dengan bahasan decision tree learning
Referensi:
Mitchell, Tom. “Machine learning.” (1997): 870-877.