Mari kita lanjutkan pembahasan paper Self-Supervised Visual Feature Learning with Deep Neural Network: A Survey dari Longlong Jing dan Yingli Tian. Pada tulisan sebelumnya telah dibahas tentang Pretext Task. Hari ini kita coba lanjutkan dengan Downstream Task
Untuk menguji kualitas fitur pada gambar dengan metode self-supervised, parameter yang dipelajari digunakan sebagai model pre-training dan kemudian di fine tune pada downstream task seperti klasifikasi image, segmentasi semantik, deteksi objek, pengenalan gerakan (action recognition) dll. Performa dari transfer learning pada high-level vision task menenjukan kemanpuan generalisasi dari fitur yang dipelajari. Bila ConvNet dapat mempelajari fitur umum (general Feature) maka model pre-training dapat digunakan sebagai titik awal yang baik untuk task vision lainnya.
Klasifikasi gambar, segmentasi semantik dan deteksi objek vuasabta digunakan oada image, sementara human acation recognition pada video.
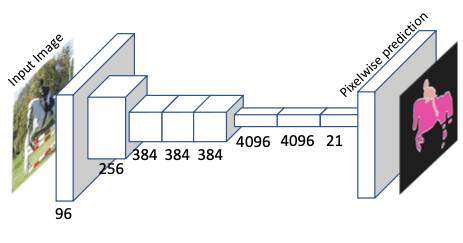
- Segmentasi semantik: adalah task untuk memberi label semantik pada setiap pixel pada gambar. Banyak digunakan oada autonomous driving, human machine interaction dan robotik. Saat ini performa pada task ini cukup menjanjikan, beberapa model yang diusulkan diantaranya Fully Convolutional Network (FCN), DeepLab, PSPNet, dan dataset seperti Pascal VOC, CityScape dan ADE20K. Diantara semua metoda tersebut, FCN adalah pelopor karena dia yang memulai penggunakan Fully Convolution Network untuk menyelesaikan task ini. Arsitektur FCN dapat dilihat pada gambar di bawah ini. Jaringan 2D ConvNet seperti AlexNet, VGG, ResNet digunakan sebagai network dasar untuk ekstraksi fitur, sementara fully connected layer digantikan dengan transposed convolution layer untuk mendapatkan dense prediction. Network ini dilatih end-to-end dengan pelabelan pixel wise. Ketika menggunakan segmentasi semantik sebagai downstream task, FCN diinisialisasi dengan parameter yang dilatih pada saat pretext task dan difine-tune pada dataset segmentasi semantik, kemudian performanya dievaluasi dan dibandingkan dengan metode self-supervised lainnya.
2. Deteksi objek: adalah task untuk mendeteksi posisi obyek pada gambar dan mengenali kategori obyek. Task ini banyak digunakan untuk autonomous driving, robotik, deteksi scene teks dll. Dataset seperti MSCOCO dan OpenImage banyak digunakan untuk task ini. Fast-RCNN adalah jaringan dua tingkat untuk deteksi obyek. Proposal obyek digenerate berdasarkan fitur map yang dihasilkan dari CNN, kemudian proposal ini dimasukan pada beberapa layer fully connected untuk menggenerate bound box dari obyek dan kategori obyek. Ketika menggunakan deteksi obyek sebagai downstream teask, network ditraining dengan pretext task pada banyak data tidak berlabel, dan menjadi model pre-training untuk Fast-RCNN, kemudian di fine tuning pada dataset deteksi obyek. Performanya diuji untuk menunjukan kemampuan generalisasi dari fitur self-supervised. Arsitekturnya bisa dilihat pada gambar berikut:

Sampai disini dulu besok insyaallah saya lanjutkan dengan task lainnya seperti klasifikasi image dll. Semoga bermanfaat!
Papernya bisa dilihat pada link berikut :