Saya lanjutkan bahasan tentang webinar inside the lab dari meta AI. Selanjutnya jerome cerita tentang tim Responsible AI (RAI) dari Meta. RAI ini melakukan riset tentang gimana ngembangin sistem AI yang responsible, maksudnya yang peduli juga tentang privacy preserving AI. Selain itu tim RAI juga melakukan publikasi sistem ranking di Instagram (pre-ranking filtering system). Terus mereka membuka juga (open source) kode torchrec. Torchrec ini library pytorch untuk sistem rekomendasi yang dipake Meta AI.
Presenter berikutnya adalah Piotr Dollar. Dia cerita tentang self-supervised vision. Dia cerita tentang perkembangan teknologi vision. Awalnya menggunakan deep learning kita bisa membuat sistem yang bisa mengenali apa isi dari sebuah gambar.

Kemudian berkembang lagi sehingga bisa mengenali posisi sebuah obyek pada gambar. Selanjutnya bisa membuat segmen-segmen obyek dari sebuah gambar

hingga kita bisa membuat sistem mengenali detail dari semua obyek pada semua gambar

Cuman perkembangan vision itu masih mengandalkan pada supervised learning, dimana semua gambar diberi anotasi atau label. Nah untuk memberi label ini adalah tantangan besar. Kalo cuman anotasi satu gambar itu mudah, tapi klo udah ribuan, bahkan jutaan gambar maka akan sangat susah. Selain itu ada bias juga, karena pelabelan dilakukan manual oleh orang. Bagaimana kalo kita gak perlu melakukan pelabelan. Caranya kita melakukan training pada sistem dengan input gambar yang dimasking, maksudnya pixelnya dihilangkan sebagian, kemudian outputnya adalah gambar yang utuh.
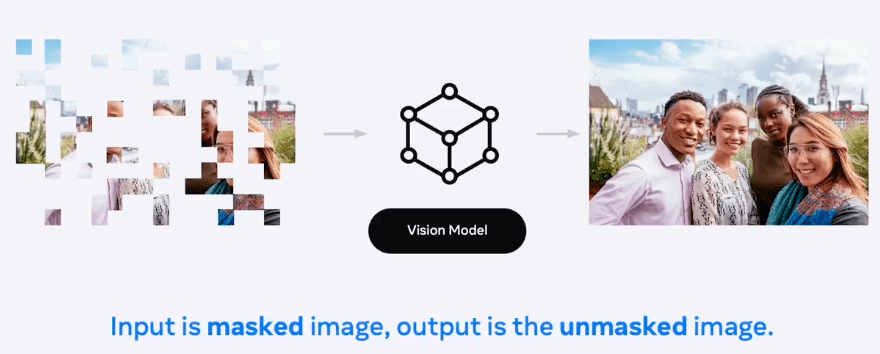
Sistem diminta membangun model yang dapat memprediksi gambar yang di masking tadi menjadi gambar yang utuh. Dengan teknik ini kita bisa melakukan rekonstruksi gambar. Tentunya sistem harus mempelajari struktur dan semantik dari gambar tersebut. Contoh hasil pengujiannya misalnya seperti gambar berikut ini:

Untuk memanfaatkan SSL ini bisa dilakukan dalam dua tahap, pertama melakukan pretraining dengan banyak data untuk melakukan prediksi.
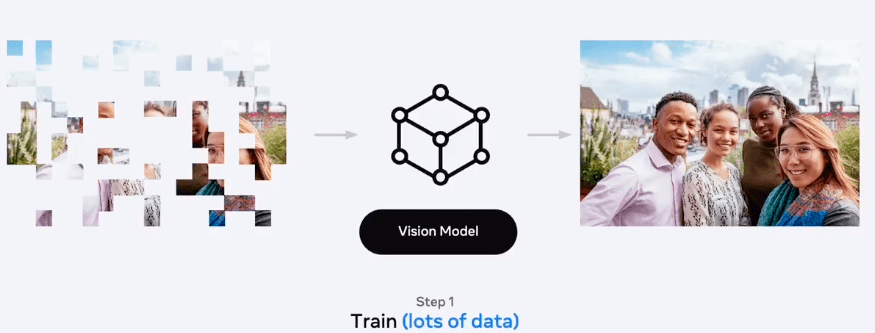
Kemudian model yang sudah dibangun dapat digunakan ditransfer untuk task lainnya dengan menggunakan data yang lebih sedikit
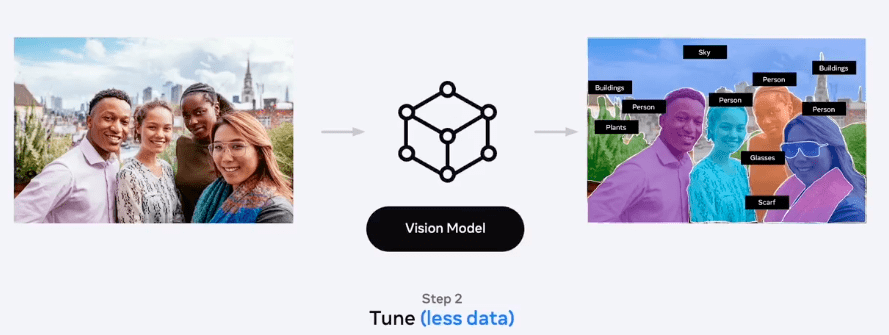
Piotr menunjukan dengan cara ini performa sistem sudah berhasil mengalahkan model yang ditraining dengan supervised learning. Kemudian kita bisa menggunakan model ini untuk task yang memiliki data yang lebih sedikit. Contohnya bisa diimplementasikan pada bidang medis yang memiliki data yang sedikit. Seperti prediksi gambar MRI. Sampai disini dulu, besok insyaAllah saya lanjutkan dengan presenter berikutnya. Semoga Bermanfaat!