Saya lanjutkan catatan dari webinar inside the lab dari Meta AI. Presenter berikutnya adalah Angela Fan. Dia bercerita tentang multi language translation.
Ada banyak banget bahasa di dunia. Menurut Angela saat ini sistem penerjemahan saat ini baru mencakup 100 bahasa. Estimasi dari Meta masih ada 4,2 milliar orang yang bahasanya belum terjangkau oleh sistem translasi saat ini. Atau sekitar 25% dari keseluruhan penduduk di dunia. Meta pengen bisa semua orang bisa mengakses teknologi tanpa ada hambatan bahasa.

Programnya meta ada 2, no language leave behind dan universal translator. Sistemnya harus mencakup speech dan text, dan tidak english sentris. Saat ini sistem translasi saat ini masih mengandalkan sistem neural network, dan melakukan bilingual translation. Maksudnya melakukan penerjemahan antara 2 bahasa. Misalnya antara Inggris dengan prancis dll. Untuk penerjamahan 2 bahasa ini dibangun sebuah model bahasa. Sehingga bila kita ingin membangun sistem penerjemahan banyak bahasa, maka kita harus membangun model bahasa yang banyak.
Sistem translasi yang ada untuk menerjemahkan 2 bahasa, umumnya masih menggunakan bahasa inggris sebagai jembatan. Maksudnya kalo saya mau nerjemahin bahasa jerman ke arab, sistem nerjemahin dulu dari jerman ke inggris, kemudian dari inggris ke arab.

Ini karena masalah teknis, misalnya karena data training dalam bahasa inggris lebih banyak. Namun meta AI sedang membangun sistem translasi yang langsung antar 2 bahasa, gak perlu menggunakan bahasa inggris sebagai jembatan. Mereka ingin membangun sistem yang bisa menyediakan support untuk 10ribu jenis terjemahan bahasa (language direction). Menurut Angela sebenarnya dalam sehari2, terjemahan langsung antara dua bahasa lebih dibutuhkan, contohnya antara spanyol dan portugis.
Cara ini juga mengurangi cascading eror. Maksudnya pada sistem lama misalnya kita menerjemahkan antara spanyol ke inggris terus ke portugis. Bila terjadi eror pada terjemahan spanyol ke inggris, maka terjemahan inggris ke portugis juga akan bertambah erornya.
Masalahnya ternyata dataset bahasa selain inggris masih sedikit, kita bisa lihat pada gambar berikut:
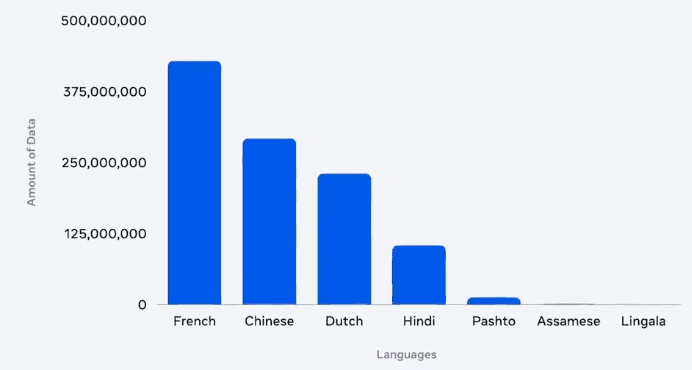
Untuk itu Meta membuat dataset bahasa ini opensource, agar dapat digunakan dan dikembangkan oleh komunitas. Contohnya dataset voxpopuli. Selain itu merekan mengembangkan model pembelajaran multimodal, yang bisa belajar dari suara dan teks. Sistem ini bikin dataset paralel automatis. (namanya laser). Sistem ini mempelajari data berbagai bahasa di dunia, dari teks dan speech, kemudian mempelajari kesamaan dan mencoba mencari pasangan kata kata kalimat dari satu bahasa ke bahasa lain. Teknik ini menggunakan self supervised learning.
Sistem translasi speech to speech antar bahasa yang ada saat ini juga masih menggunakan intermediary atau jembatan. Jadi speech diubah jadi text, kemudian text diterjemahkan baru kemudian hasil terjemahannya dibuat speech seperti bagan berikut:
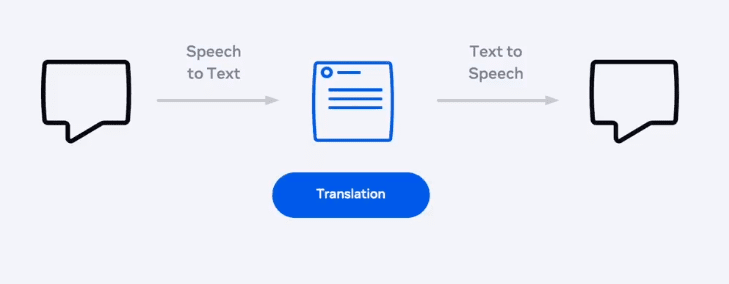
Meta sedang mengembangkan sistem translasi speech-to speech yang langsung. Sistem multilingual yang dibangun ternyata telah menghasilkan performa yang baik. Bisa dilihat pada gambar berikut:

Sampai disini dulu, insyaallah besok saya lanjutkan dengan presenter berikutnya.