Pada tulisan sebelumnya telah dibahas tentang supervised learning dan klasifikasi. Sekarang akan diceritakan beberapa contoh implementasi klasifikasi dengan machine learning.
Klasifikasi dokumen dan Filtering email spam
Pada klasifikasi dokumen, tujuan pembelajaran adalah untuk melakukan klasifikasi input seperti halaman web atau pesan email menjadi kelas C tertentu p(y = c|x, D), x biasanya adalah input teks tertentu. Contoh kasus klasifikasi dokumen adalah email spam filtering, dimana kita mengklasifikasikan email spam yaitu y = 1 atau tidak spam y = 0.
Umumnya kasifier menggunakan asumsi vektor input x memiliki ukuran yang sudah ditentukan (fixed size). Teknik untuk merepresentasikan dokumen ke format feature vektor adalah menggunakan representasi bag of words. Yaitu untuk mencari apakah kata tertentu (j) muncul di dokumen (i). Kemudian dibuat matrix kemunculan kata pada dokumen. Contohnya pada deteksi spam, kemungkinan besar pesan spam memiliki kata “buy”, “cheap”, “viagra”, dll
Klasifikasi Bunga
Contoh lainnya adalah penelitian Ronald Fisher tentang klasifikasi 3 jenis bunga iris yaitu setosa, versicolor dan virginica. Ahli biologi telah membuat 4 fitur atau karakteristik yaitu panjang kelopak (sepal length), lebar kelopak, panjang mahkota (petal) dan lebarnya. Ekstraksi fitur ini penting, namun sulit. Umumnya machine learning menggunakan fitur yang dipilih oleh manusia.
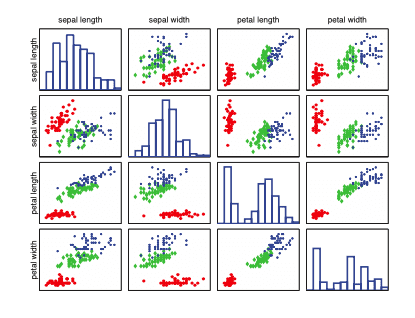
Bila kita membuat scatter plot dari data iris, maka akan mudah untuk membedakan setosa dibandingkan dua kelas lainnya berdasarkan panjang mahkotanya atau lebarnya. Merah bulat = setosa, hijau segi empat = versicolor, biru bintang = virginica. Namun membedakan versicolor dari virginica lebih susah. Untuk ini dibutuhkan setidaknya 2 fitur. Sangat penting untuk melakukan analisa data secara keseluruhan exploratory data analysis, seperti melakukan ploting data, sebelum menerapkan metode machine learning.
Klasifikasi gambar dan pengenalan tulisan
Permasalahan klasifikasi lain yang lebih sulit adalah klasifikasi gambar (image classification). Klasifikasi ini tidak dilakukan pre-prosesing sebelumnya oleh manusia. Contohnya mesin diminta melakukan klasifikasi gambar, apakah gambar di dalam ruangan, atau di luar ruangan? apakah foto dalam format horisontal atau vertikal? apakah ada kucing atau tidak pada foto tersebut?
Pada kasus dimana gambar adalah tulisan tangan dan angka, misalnya kode pos pada sebuah surat, maka digunakan teknik pengenalan tulisan tangan (handwriting recognition). Dataset standar yang digunakan adalah MNIST yaitu “Modified National Institute of Standards”. Kata modified digunakan karena gambarnya telah dilakukan preprosesing untuk untuk memastikan digitnya ada di tengah-tengah gambar. Dataset ini terdiri dari 60 ribu gambar untuk traning dan 10 ribu gambar untuk pengujian dengan digit dari 0-9 yang ditulis oleh berbagai macam orang. Ukuran gambar adalah 28×28 dan memiliki nilai grayscale 0-255.
Banyak metode klasifikasi generik yang mengabaikan struktur dari fitur input, seperti layout spatial. Contohnya gambar tulisan tangan yang dipermutasi secara random. Fleksibiltas dari metode generik adalah keuntungan dan kerugian. Keuntungannya adalah bisa digunakan untuk berbagai macam task. Kerugiannya adalah metode ini mengabaikan informasi penting.
Deteksi dan pengenalan Wajah
Tugas yang lebih rumit dalam gambar adalah deteksi obyek atau lokalisasi obyek. Kasus khusus dari klasifikasi ini adalah deteksi wajah. Satu pendekatan adalah membagi gambar menjadi beberapa patch kecil pada lokasi berbeda, pada skala dan orientasi berbeda dan melakukan klasifikasi patch tersebut berdasarkan apakah terdapat tekstur seperti wajah atau tidak. Teknik ini disebut sliding window detector.
Sistem akan menghasilkan lokasi dimana probabilitas adanya wajah cukup tinggi. Sistem deteksi wajah ini sekarang digunakan pada kamera digital. Lokasi wajah yang dideteksi digunakan untuk menentukan titik autofokus. Implementasi lainnya adalah untuk melakukan pemburaman wajah secara otomatis pada sistem google street view.
Setelah berhasil mendeteksi wajah, maka akan dilanjutkan dengan pengenalan wajah, yaitu memprediksi identitas orang tersebut. Pada kasus ini jumlah label kelas akan sangat besar. Fitur yang digunakan juga berbeda dengan deteksi wajah. Untuk pengenalan wajah, perbedaan antara berbagai wajah seperti haya rambut menjadi penting untuk identifikasi wajah, tapi tidak penting untuk deteksi wajah. Pada deteksi wajah, detail seperti ini tidak penting, tapi hanya fokus untuk membedakan wajah dengan bukan wajah.
Sampai disini dulu, Insyallah nanti saya akan lanjutkan dengan regresi. Semoga Bermanfaat!
Referensi
Murphy, K. P. (2012). Machine learning: a probabilistic perspective. MIT press.