Mari kita lanjutkan pembahasan kuliah tentang SSL dari Ishan Misra. Pada tulisan sebelumnya telah dibahas tentang proses training pada SwAV. Hari ini kita lanjutkan tentang bagaimana performa SwAV. Performa SwAV dilakukan dengan melakukan transfer learning, seperti pada label berikut:

Transfer learning bisa dievaluasi dengan dua task berikut:
- klasifikasi dengan linear classifier dan fiturnya udah fixed,
- deteksi full network dengan fine tuned fitur.
Pada percobaan pertama jaringan supervised di training dengan model ImageNet kemudian di transfer ke downstream task. Supervised learning menghasilkan performa yang baik pada ImageNet. Ini sesuai dengan ekspektasi, karena jaringan di training dengan imageNet dan dilakukan pengujian dengan set validasi dari ImageNet. Sehingga fitur yang dipelajari pada waktu training sangat berhubungan (aligned) dengan downstream task. Begitu juga dengan model Places dan iNatularils.
Namun bila kita lihat pada task deteksi, self Supervised telah menghasilkan performa yang lebih baik dibandingkan supervised learning. Kemudian bila kita lihat performa SwAV berhasil mendekati performa Supervised learning pada imageNet. Bahkan melampaui performa supervised pada model lainnya.
Pada pretraining dipelajari fitur generik dari gambar. Sementara model Places adalah untuk mengidentifikasi gambar lokasi/tempat, misalnya gambar Mall, Gereja, pantai dll. Pada ImageNet hanya ada sedikit kelas yang berisikan gambar tentang tempat/lokasi. Kita bisa lihat pada supervised learning, model berhasil mempelajari fitur dengan baik pada imageNet, tapi ketika dilakukan transfer learning ke dataset Places, performanya tidak terlalu bagus, karena fiturnya menjadi sangat spesifik terhadap gambar pada ImageNet saja.
Sementara pada self-supervised pre-training, model mempelajari fitur tanpa tahu banyak tentang label dari ImageNet. Sehingga lebih mudah mempelajari fitur general, sehingga ketika dilakukan transfer ke places, dimana hanya ada sedikit overlap dengan konsep ImageNet, performanya lebih baik dibandingkan supervised learning.
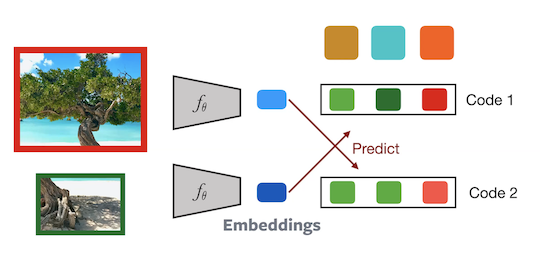
Bagaimana kita melakukan analisa cost function bila kita memiliki multiple clusters untuk embedding, yang tidak spesifik ke negatif sampel? Bagaimana model menentukan cluster mana yang cocok untuk embedding?
Pada inisialisasi kita memiliki beberapa prototipe random. Ketika kita melakukan feed forward embedding dari 2 crop,seperti gambar aslinya. Mereka menjadi lebih related dibandingkan embedding dari crop lain. Bayangkan ini sebagai prediksi random, dimana prototipe adalah random fitur vektor. Kita mengambil embedding biru dan menghitung prediksi random pada set prototipe. Pada embedding hijau juga sama. Pada inisialisasi, embedding biru akan memiliki signature (code) yang berbeda dibandingkan embedding hijau. Sehingga bisa dikatakan kita melakukan bootsrapping signal tersebut, yaitu kita mengambil signal tersebut dan terus diperkuat. Jadi pada saat inisialisasi nilainya adalah random,dengan signature yang berbeda, tapi kemudian kita ingin tetap memiliki signature yang berbeda. Sehingga ketika training dilanjutkan, signaturenya menjadi semakin berbeda.
Berikut ini adalah keuntungan dari metode SwAV:

Sampai disini dulu, besok insyaallah akan saya lanjutkan. Semoga Bermanfaat!
Kode dan model bisa dilihat di :
https://github.com/facebookresearch/swav
Materi kuliahnya:
https://atcold.github.io/NYU-DLSP21/en/week10/10-1/
slidenya ada disini:
https://drive.google.com/file/d/1BQlWMVesOcioW69RCKWCjp6280Q42W9q/edit
Videonya: