Saya lanjutkan pembahasan tentang kuliah tentang SSL dari Ishan Misra. Pada tulisan sebelumnya telah dibahas tentang SwAV dan perbedaan antara data pada dunia nyata dengan dataset ImageNet. Hari ini kita akan bahas tentang SEER.
SEER: Learning from uncharted Images
Dibandingkan dengan dataset Imagenet, pada dunia sebenernya gambar dapat memiliki distribusi yang berbeda, dan bisa saja tidak memiliki obyek prominent. Untuk melakukan verifikasi apakah model bekerja dengan baik pada gambar yang tidak ada di ImageNet, maka Ishan mencoba melakukan pengujian metoda Swav. SEER adalah metode Swav yang diuji pada 1,3 milliar gambar random yang tidak difilter.
Gambar dibawah menampilkan performa fine tune dari empat model yang ditransfer dengan Imagenet. Pada garis biru terlihat performa SEER, yang merupakan model regnet yang ditrain dengan 1,3 miliar gambar random dari internet. Kemudian ada model SwAV yang merupakan model ResNet yang ditrain pada Imagenet. Kemudian ada model SimCLRv2 yang merupakan modifikasi model Resnet pada Imagenet. Dan terakhir ada Vision transformer yang di train pada ImageNet.
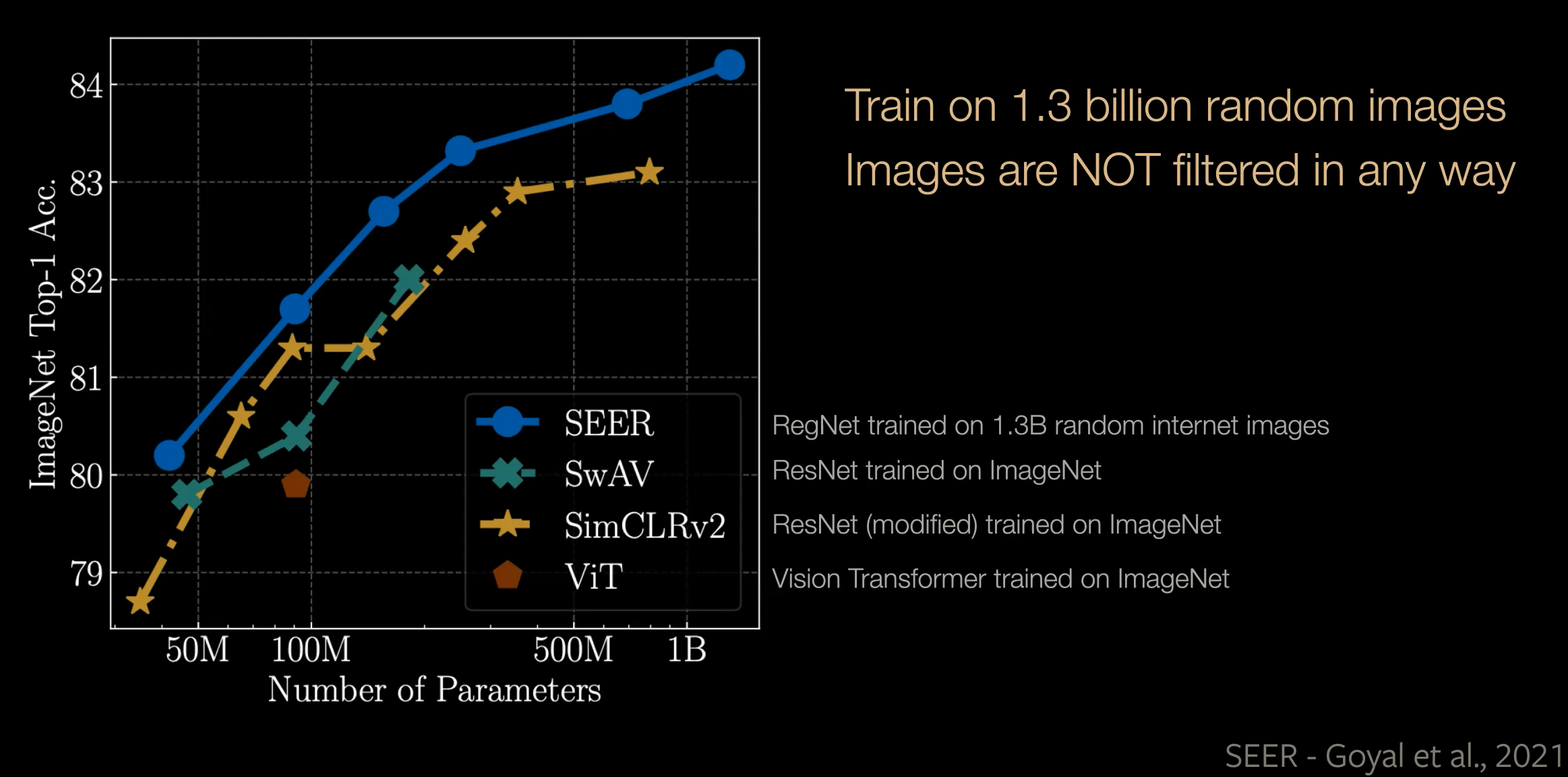
SEER menghasilkan performa yang baik. Pada grafik sumbu x adalah jumlah parameter, sumbu y adalah akurasi yang dihasilkan. Setiap titik merepresentasikan model yang berbeda. Kita dapat melakukan training dengan miliaran gambar yang dapat ditransfer dengan baik ke Imagenet. Semua ini dilakukan pada gambar internet random, tanpa dilakukan penyusunan gambar maupun label.
Selanjutnya kita akan melihat bagaimana perbedaan kinerja pada data yang dipilih dan dengan mengabaikan metadata. Performa SEER dapat dibandingkan dengan model yang ditrain dengan network yang ditraining dengan data yang dipilih dengan weak supervision
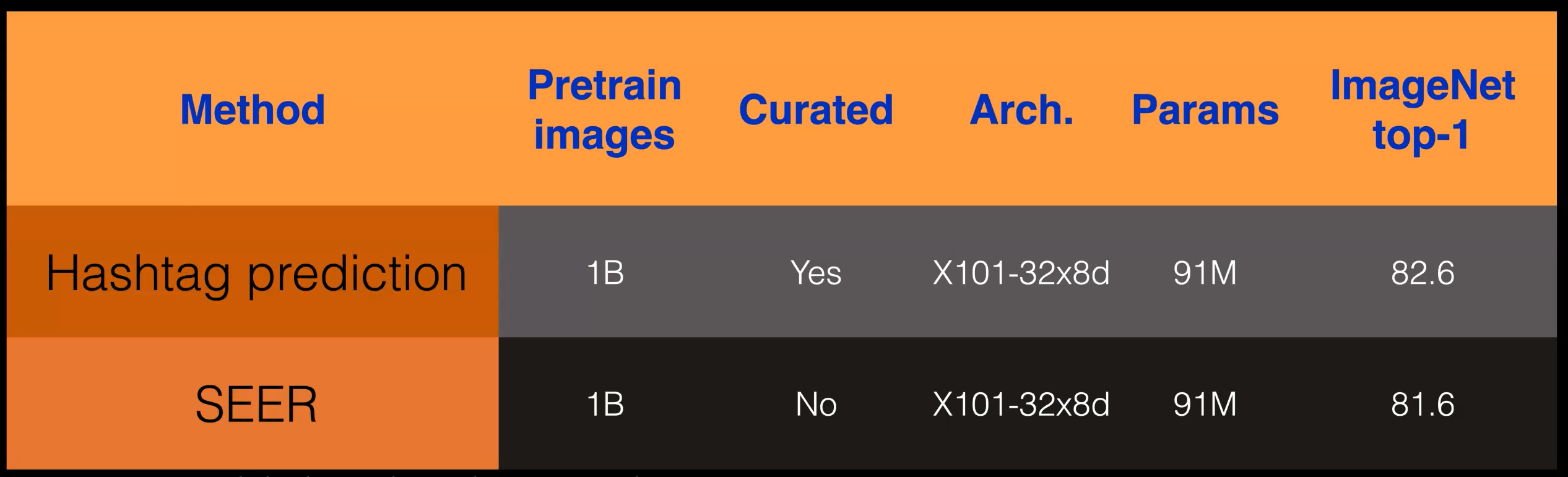
Pada baris atas kita liat metode prediksi hashtag yang dipretraining dengan 1 milliar gambar. Gambar-gambar ini sudah dipilih sehingga hashtagnya sesuai dengan kelas ImageNet. Sehingga bila ada gambar yang hashtag nya tidak ada pada kelas Imagenet, maka gambarnya akan difilter.
Dengan filtering ini, maka diharapkan diperoleh dataset pretraining yang sesuai (aligned) dan mudah, yang kemudian ditransfer ke ImageNet. Data ini kemudian ditraining dengan 91 juta parameter (top 1 model) dan arsitektur resnetxt-101-32x8d menghasilkan akurasi 82,6%.
Sementara itu untuk SEER, datanya tidak difilter, ada 1 milliar juga, tidak menggunakan prediksi hastag. SEER adalah self supervised, menghasilkan performa 81,6% cuman berbeda 1% dibandingkan hastag prediction. Sehingga SSL dapat menghasilkan proses inisialisasi dengan baik. Sehingga kita bisa
Sampai disini dulu, besok insyaAllah akan saya lanjutkan dengan metoda AVID+CMA. Semoga Bermanfaat!
Kode dan model bisa dilihat di :
https://github.com/facebookresearch/swav
Materi kuliahnya:
https://atcold.github.io/NYU-DLSP21/en/week10/10-1/
slidenya ada disini:
https://drive.google.com/file/d/1BQlWMVesOcioW69RCKWCjp6280Q42W9q/edit
Videonya: