Saya lanjutkan pembahasan paper Self-supervised Visual Feature Learning karya Jing & Tian. Pada tulisan sebelumnya sudah dijelaskan tentang diagram sistem self-supervised learning. Ada beberapa istilah baru disana yaitu:
- pseudo label adalah label yang digenerate automatik berdasarkan atribut data pada waktu pretext task.
- Pretext-task adalah task yang dirancang untuk diselesaikan oleh jaringan untuk mempelakari visual fitur. Hasilnya adalah model pre-training
- Downstream task adalah aplikasi vision yang digunakan untuk menguji kualitas fitur dari SSL. Aplikasi ini menggunakan model pre-trained hasil pretext task. Dapat digunakan untuk data yang terbatas. Secara umum seperti supervised learning yaitu menggunakan data berlabel. Namun pada beberapa aplikasi dapat juga seperti pretext task, tidak menggunakan data berlabel
- Semi-supervised adalah metode learning dengan menggunakan sedikit data berlabel dan banyak data tidak berlabel
- Weakly-supervised adalah metode learning yang menggunakan label kasar atau tidak akurat. Contohnya labelnya didapat dari hashtag
Self-supervised membutuhkan dataset besar namun menghasilkan performa yang bersaing dengan metoda supervised.
Ada beberapa arsitektur yang sering digunakan untuk vision diantaranya:
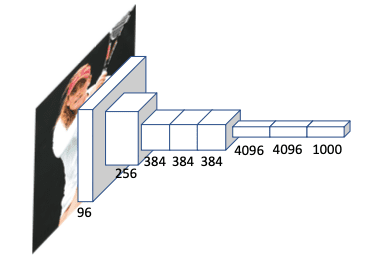
- AlexNet: menghasilkan performa yang baik untuk klasifikasi image pada dataset ImageNet. Dengan beberapa GPU yang canggih dapat menghasilkan 62,4 juta parameter ketika ditraining pada ImageNet dengan 1,3 juta gambar. Memiliki 8 layer dimana 5 adalah layer convolusi dan 3 adalah fully connected (FC) layer. ReLU digunakan pada setiap layer convolusi. 94% parameter jaringan berasal dari layer FC. Namun jaringan dapat menghasilkan over-fit. Sehingga berbaga teknik digunakan untuk menghindari masalah overfitting diantaranya augmentasi data, dropout dan normalisasi.
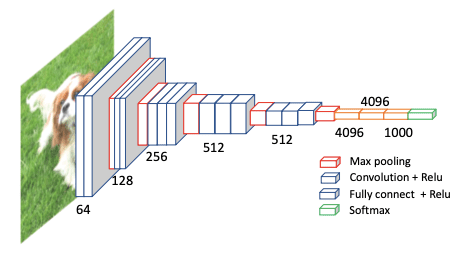
- VGG diajukan Simonyan dan Zisserman dan menjadi juara kompetisi ILSVRC 2013. Mereka mengajukan beberapa jaringan dengan depth berbeda. Namun yang banyak digunakan adalah VGG 16 layer karena performanya yang baik walaupun ukurannya tidak terlalu besar. Memiliki 16 layer convolusi dalam 5 blok. Perbedaan VGG dan AlexNet adalah alexnet memiliki stride konvolusi besar dan ukuran kernel besar. Sementara VGG memiliki kernel lebih kecil 3×3 dan stride 1×1. Kernel besar menghasilkan banyak parameter dan ukuran model yang besar, sementara ukuran stride besar membuat jaringan tidak mendapatkan fitur halus pada lower layer. Ukuran kernel yang kecil membuat training pada Deep-CNN masih memungkinkan dengan tetap memperoleh informasi yang tepat pada jaringan.
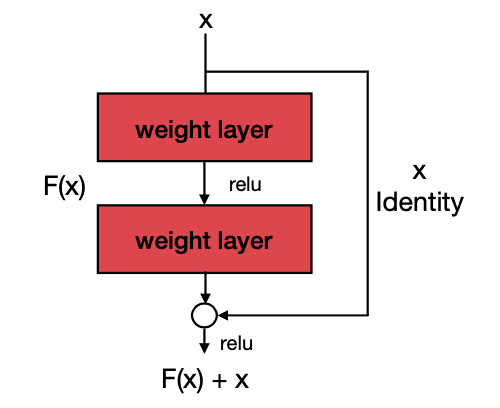
3. ResNet: VGG menunjukan bahwa Deeper network dapat menghasilkan performa yang lebih baik. Namun Deeper network lebih sulit untuk ditraining, karena ada dia masalah yaitu vanishing gradient dan gradient explosion. Resnet diusulkan oleh He et.al untuk menggunakan skip connection pada blok convolusi dengan mengirimkan fitur map sebelumnya ke blok konvolusi berikutnya untuk mengatasi masalah vanishing gradient dan gradient explosion. Dengan skip connection, training deep neural network pada GPU menjadi lebih memungkinkan. He et.al juga mencoba beberapa jaringan dengan depth yang berbeda untuk klasifikasi gambar. Karena ukuran modelnya yang lebih kecil dan performanya yang baik, ResNet sering digunakan sebagai base network untuk task vision lainnya. Blok konvolusi dengan skip connection juga banyak digunakan sebagai blok dasar.
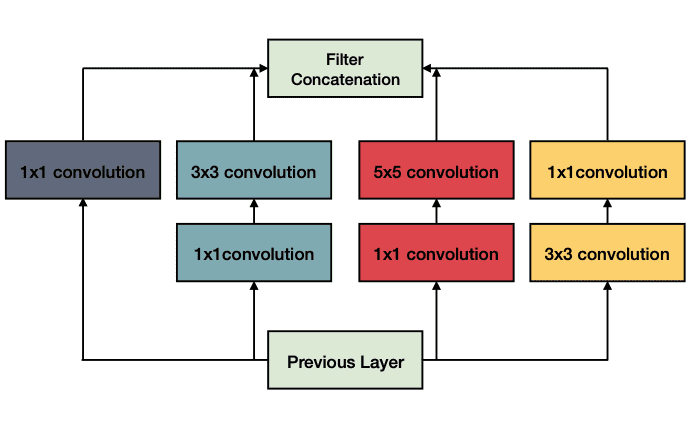
4. GoogLeNet adalah deep network 22 layer diajukan oleh Szegedy et.al yang memenangkan kompetisi ILSVRC 2014 dengan akurasi top 5 93,3%. Dibandingkan penelitian lainnya yang fokus membangun deeper network, Szegedy mencoba membangun sebuah jaringan yang lebih lebar. Maksudnya setiap layer memiliki beberapa layer konvolusi paralel. Blok dasar GoogLeNet adalah blop insepsi yang terdiri dari 4 layer konvolusi paralel dengan ukuran kernel berbeda dan diikuti oleh konvolusi 1×1 untuk tujuan dimension reduction. Metode ini menampah depth dan width network namun komputasi tetap konstan. Arsitektur untuk blok inception bisa dilihat pada gambar dibawah.
5. DenseNet. Jaringan seperti AlexNet, VGG dan ResNet menggunakan arsitektur hierarkis. Gambar di masukan ke network dan fitur diekstrak dengan layer-layer yang berbeda. Shallow Layer mengekstrak fitur umum low-level, sementara deep layer mengekstrak fitur spesifik dan high-level. Namun, bila jaringan semakin banyak (deep), deeper layer dapat mengalmi masalah menyimpan fitur low-level yang dibutuhkan oleh jaringan untuk menyelesaikan task. Untuk mengatasi masalah ini, Huang et.al mengajukan dense connection untuk mengirim semua fitur sebelum blok konvolusi sebagai input ke blok konvolusi berikutnya dalam neural network. Pada gambar dibawah ini terlihat, fitur output dari blok konvolusi sebelumnya menjadi input pada blok saat ini. Dengan cara ini shallower block dapat fokus pada fitur general low-level sementara deeper block dapat fokus pada fitur spesifik task yang high level.
Sampai disini dulu, insyaAllah besok saya lanjutkan pembahasan tentang paper ini.
Papernya bisa dilihat pada link berikut :