Saya lagi baca tulisan peneliti dari Meta AI tentang self-supervised Transformer. Menurut Piotr Bojanowski dkk, inovasi terbaru di bidang AI saat ini ada 2 yaitu Self-supervised learning (SSL) dan transformer. SSL membantu mesin untuk belajar dari data tidak berlabel dan acak. Sementara itu transformer membantu model AI untuk memilih fokus pada bagian tertentu dari input, yang membuat sistem lebih efektif.
Peneliti Meta AI bekerjasama dengan Inria telah mengembangkan metode baru yang dinamakan DINO. Dino melakukan trining Vision Transformer (ViT) tanpa supervisi. Dino yang menggabungkan SSL dengan transformer. Dino mampu mencari dan melakukan segmentasi obyek pada gambar maupun video tanpa supervisi, dan tanpa ditentukan target segmentasinya sebelumnya. Dengan cara ini model dapat memahami video maupun gambar dengan lebih baik.
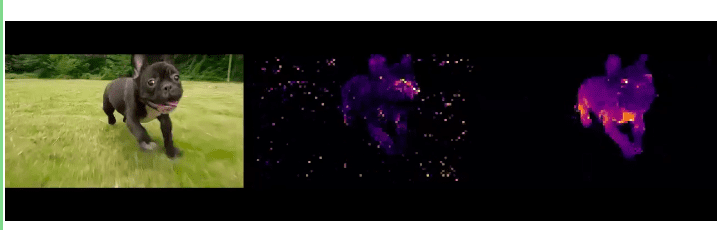
Contyhnya pada gambar terlihat ada 3 gambar. Gambar kiri adalah input, gambar tengah adalah hasil segmentasi menggunakan metode supervised, gambar kanan adalah hasil segmentasi dengan DINO.
Segmentasi obyek sangat berguna untuk berbagai task seperti mengganti background dari video chat, atau mengajarkan robot untuk melewati (navigasi) sebuah daerah yang padat. Segmentasi disebut sebagai salah satu tantangan yang berat pada Vision, karena mesin harus memahami isi gambar.
Segmentasi umumnya dilakukan dengan metode supervised dan membutuhkan banyak dataset berlabel. Namun Dino berhasil melakukan segmentasi dengan self-supervised dan transformer.
Pada komputer vision, selain performa tinggi, efisiensi juga penting. Efisiensi yang baik membuat training tidak memerlukan komputasi tinggi. Model PAWS dapat melakukan training dengan komputasi lebih rendah. PAWS melakukan pretraining model ResNet-50 dengan hanya menggunakan 1% label di ImageNet, dengan akurasi tinggi dengan langkah pretraining 10 kali lebih sedikit.
Dengan DINO dan PAWS, sistem vision dapat dibangun dengan label yang lebih sedikit dan komputasi lebih rendah. Sistem self-supervised yang ditraining dengan ViT menunjukan potensi yang menjanjikan. Kode sistem ini bisa dilihat pada web ini dan disini.
Self-supervised learning dengan Vision
Transformers telah menghasilkan performa yang baik di artificial intelligence, termasuk NLP, vision dan speech. Training dengan ViT dan DINO, model dapat mempelajari representasi secara otomatis, dan memisahkan obyek dengan background. Segmentasi obyek dilakukan tanpa anotasi manual atau dedicated dense pixel-level loss.
Komponen utama dari Vision Transformer adalah layer self-attention. Pada model ini setiap lokasi spatial membangun representasinya dengan hadir “attending” ke lokasi lain. Dengan cara “looking” at other, yaitu bagian gambar yang jauh (potentially distant pieces of the image), model membangun pemahaman yang baik terhadap gambar.
Pada visualisasi attention maps di jaringan, kita dapat melihat hubungan ke coherent semantic regions pada gambar. Sampai disini dulu, besok saya lanjutkan pembahasan tentang DINO.
Referensi: