Hari ini saya lanjutkan pembahasan kuliah Ishan Misra tentang Self-supervised Learning. Pada tulisan sebelumnya kita sudah mengenal tentang teknik contrastive learning, dan metode PIRL. Disana dibahas juga tentang pentingnya mendapatkan pasangan yang negatif untuk meningkatkan performa contrastive learning. Menurut Ishan ada 3 teknik yang bisa digunakan untuk mendapatkan sampel negatif. Hari ini kita akan bahas tentang salah satu tekniknya yaitu SimCLR.
SimCLR adalah singkatan dari Simple Framework for Contrastive Learning of Visual Representations. Pada teknik ini dari sebuah gambar dibuat dua (correlated views) dengan teknik augmentasi seperti random cropping, resize, color distortions dan Gaussian blur.

Sebuah base encoder digunakan dengan digunakan dengan sebuah proyeksi untuk mendapatkan representasi yang akan digunakan untuk melakukan contrastive learning
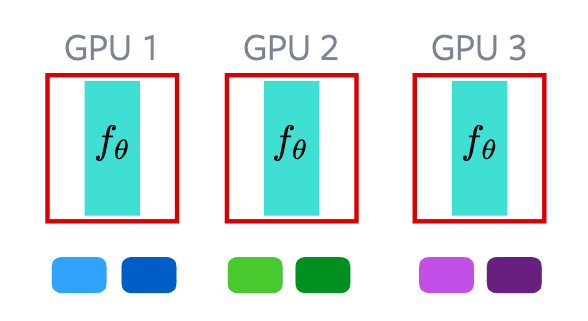
Teknik ini menggunakan ukuran batch yang besar untuk menggenerate sampel negatif. Batch dapat disebar pada berbagai GPU secara independen. Gambar yang digenerate pada sebuah GPU dapat dianggap sebagai sampel negatif dari GPU lain. Teknik ini mudah untuk diimplementasikan, namun membutuhkan ukuran batch yang besar dan membutuhkan jumlah GPU yang besar. Contohnya pada gambar diataskita menggunakan 3 GPU. Untuk membuat sampel negatif, kita membuat batch yang besar. Setiap GPU kita feed forward gambarnya secara independen. Sehingga kita mendapatkan embedding pada masing-masing GPU. Untuk menggunakan sampel negatif, kita memilih embedding dari gpu yang lain.
Untuk mengatasi kebutuhan komputasi besar pada metode ini dapat digunakan Memory Bank.
Memory bank dapat digunakan untuk menjaga sebuah momentum aktivasi antara semua fitur. Bila kita punya 1000 sampel dari dataset, kita memiliki 1000 memori bank. Setiap kali gambar di forward pass, memory bank akan melakukan update pada embedding baru. Memory bank ini dapat digunakan sebagai negatif dari contrastive loss.
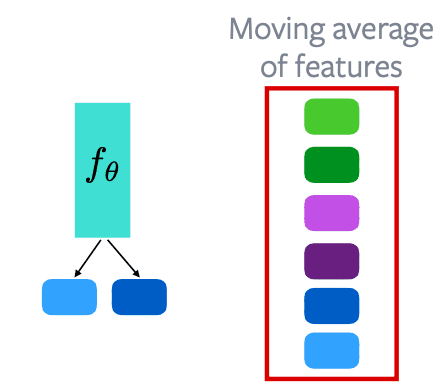
Keuntungan dari memory bank:
- lebih efisien dari komputasi. membutuhkan hanya sebuah forward pass untuk menghitung embedding.
Kerugian memory bank:
- Tidak online. Fitur cepat menjadi basi. Hanya diupdate sekali pada setiap epoch
- Membutuhkan RAM GPU yang besar. Bila dataset kita 1000 sampel maka dia membutuhkan fitur 1 juta, dan kebutuhan memori akan terus bertambah
- Sulit untuk mengatur penyimpanan pada jutaan gambar
Sampai disini dulu, besok insyaallah akan saya lanjutkan dengan teknik MoCo. Semoga bermanfaat!
Materinya bisa dilihat pada link berikut:
https://atcold.github.io/NYU-DLSP21/en/week10/10-1/
slidenya ada disini:
https://drive.google.com/file/d/1BQlWMVesOcioW69RCKWCjp6280Q42W9q/edit
Videonya: