Saya lanjutkan pembahasan kuliah tentang self supervised Vision dari Ishan misra. Sebelumnya telah dibahas tentang clustering dan SEER, sekarang kita lanjutkan dengan AVID CMA (Audio video instance discrimination -with cross modal agreement). Metoda ini menggabungkan contrastive learning dengan clustering.

Bila sebelumnya yang dipelajari adalah image, kali ini adalah video. AVID adalah metode untuk membandingkan audio dan video. Jadi kita punya 2 encoder, video encoder dan audio encoder. Video dimasukan ke video encoder kemudian didapatkan embedding, audio dimasukan ke audio encoder dan kita dapatkan embedding. Video embedding dan audio embedding dari sampel yang sama harus berada dalam feature space yang dekat (related) disebut positive. Untuk video dan audio yang tidak related disebut negative. Konsep ini adalah contrastive learning.
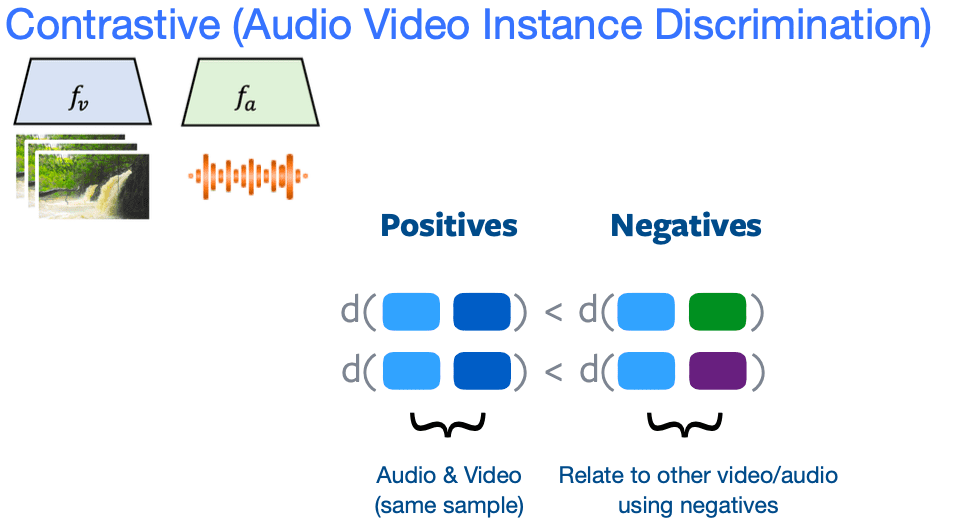
Sementara untuk clustering, kita expand (perluas) notion dari positive, maksudnya kita ambil sebuah titik reference, contohnya dari grafik dibawah, dan dihitung kemiripan dari embeddingnya baik video atau suara ke semua sampel data pada dataset. Untuk sampel2 yang memiliki kemiripan tinggi untuk video dan audio kita sebut positif. Hal ini adalah clustering. Berbeda dengan contrastive learning, dimana kita punya konsep positif yang lebih terbatas, yaitu video dan audio harus berasal dari sampel yang sama. Atau pada kasus image, harus image yang sama dengan augmentasi yang berbeda.
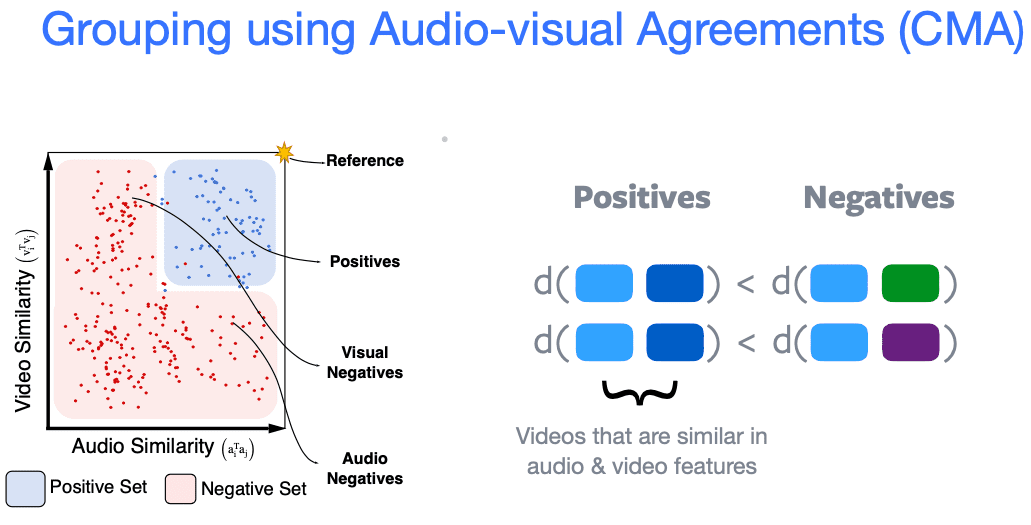
Pada kasus ini kita mencari positif dari beberapa sampel sekaligus,caranya dengan menghitung kemiripan dari video space dan audio space. Ini yang disebut audio-video agreement (CMA).
Seperti apa sampel2 ini ini? Dari gambar dibawah terlihat di atas kita memiliki 3 reference. Kemudian baris berikutnya yang positif, baris berikutnya visual negatif dan audio negatif.
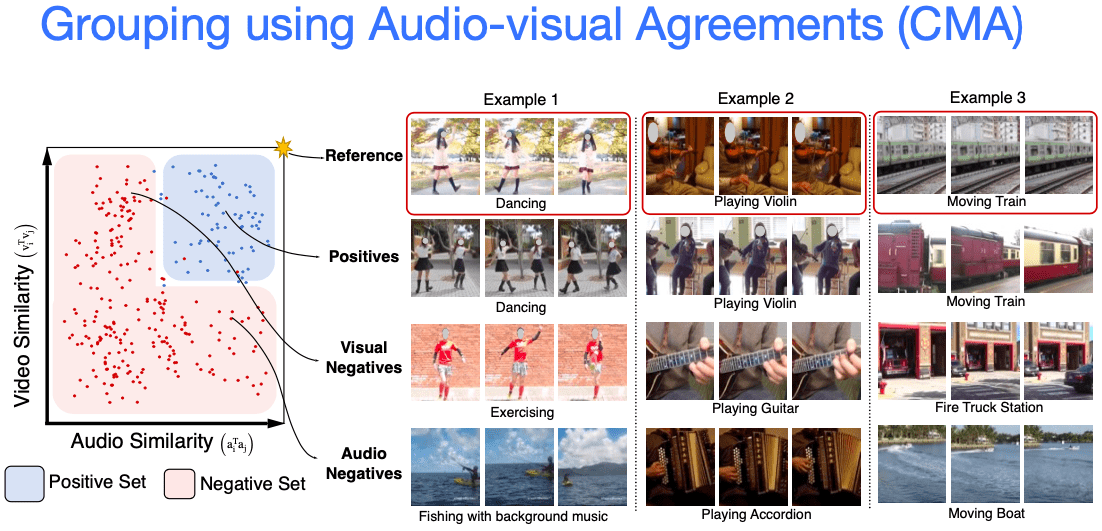
Pada contoh 1 adalah video orang menari, yang positif adalah video dan audio orang menari juga. Sementara itu untuk visual negatif bisa kita lihat video orang sedang senam, yang terlihat mirip dengan menari. Sementara untuk audio negatif terlihat secara pada audio untuk orang sedang memancing tapi sedang mendengarkan musik. Musiknya mungkin terlihat mirip dengan audio orang menari.
Begitu juga pada contoh tiga, video kereta sedang bergerak, yang kita bandingkan dengan video mobil pemadam kebarakan, serta video kapal sedang bergerak.
Dengan melakukan ini, kita dapat mengembangkan set positif, dan menggabungkan contrastive learning dan clustering. Sampai disini dulu, besok insyaAllah saya lanjutkan tentang materi disillation.
Semoga bermanfaat!
kode:
https://github.com/facebookresearch/AVID-CMA
Materi kuliahnya:
https://atcold.github.io/NYU-DLSP21/en/week10/10-1/
slidenya ada disini:
https://drive.google.com/file/d/1BQlWMVesOcioW69RCKWCjp6280Q42W9q/edit
Videonya: