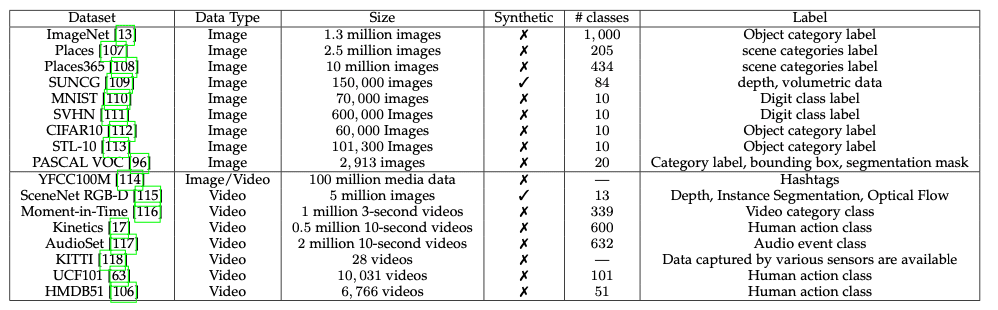
Saya lanjutkan pembahasan paper Self-Supervised Visual Feature Learning with Deep Neural Network: A Survey dari Longlong Jing dan Yingli Tian. Pada tulisan sebelumnya telah dibahas tentang Downstream Task. Sekarang saya lanjutkan tentang macam-macam dataset yang bisa digunakan di Downstream Task untuk pengujian model SSL. Berikut ini beberapa dataset image:
ImageNet
Dataset ImageNet memiliki 1,3 juta gambar yang terbagi secara merata dalam 1.000 kelas. Kelas-kelas ini diatur berdasarkan hirarki WordNet. Setiap gambar hanya mendapatkan 1 label. ImageNet adalah dataset yang paling banyak digunakan untuk learning fitur image pada self-supervised
Places
Dataset ini diusulkan untuk task scene recognition, dan memiliki lebih dari 2,5 juta gambar, terdiri dari 205 kategori scene, dimana ada kurang lebih 5000 gambar pada setiap kategori.
Places365
Dataset ini merupakan generasi kedua dari dataset Places yang dibangun untuk high-level visual understanding tasks, seperti scene context, object recognition, action prediction, event prediction, dan teori mind inference. Ada lebih dari 10 juta gambar yang dibagi dalam 400 kelas dan 5.000- 30.000 gambar untuk training pada setiap kelas.
SUNCG
Dataset SUNCG adalah repositori 3D scene untuk indoor, terdiri dari 45.000 scene berbeda seperti dengan denah ruangan dan layout perabotan yang dibuat secara manual. Dataset ini memiliki label synthetic depth, object level semantic labels, dan volumetric ground truth.
MNIST
MNIST adalah dataset tulisan tangan terdiri dari 70.000 gambar terbagi menjadi 60.000 gambar untuk training set dan sisanya 10.000 gambar untuk testing. Semua digit telah dinurmalisasi ukurannya dan diatur posisinya di tengah (centered) dengan ukuran tetap.
SHVN
SVHN adalah dataset untuk pengenalan digits dan angka pada gambar natural scene yang didapatkan dari gambar nomer rumah pada Google Street View images. Dataset ini memiliki 600.000 gambar dan semua digit memiliki resolusi tetap 32 × 32 pixel
CIFAR10
Dataset ini adalah kumpulan gambar kecil untuk task klasifikasi. Memiliki 60.000 ribu gambar dengan ukuran 32 × 32 dengan 10 kelas berbeda. 10 kelas ini diantaranya pesawat, mobil, burung, kucing, rusa, anjing, kodok, kuda, kapal, dan truk. Dataset ini balanced dan ada 6.000 gambar pada setiap kelas.
STL-10
Dataset STL-10 dirancang khusus untuk pengembangan pembelajaran fitur unsupervised. Dataset ini terdiri dari 500 gambar berlabel untuk training, 800 gambar untuk testing, dan 100.000 gambar tidak berlabel dengan 10 kelas diantaranya pesawat, burung, mobil, kucing, rusa, anjing, kuda, monyek, kapal dan truk.
PASCAL Visual Object Classes (VOC):
Dataset VOC 2.012 memiliki 20 kategori obyek diantaranya kendaraan, perabotan, hewan, pesawat, sepeda, kapal,bis, mobil, motor, kereta, botol, kursi, meja makan, tanaman di pot, sofa, TV/monitor, burung, kucing, sapi, anjing, kuda, domba dan orang. Setiap gambar memiliki anotasi pixel-level segmentation, anotasi bounding, dan anotasi kelas obyek. Dataset ini telah banyak digunakan sebagai benchmark untuk deteksi obyek, segmentasi semantik dan klasifikasi. Dataset ini dibagi menjadi 3 bagian: 1.464 gambar untuk training, 1.449 gambar untuk validasi dan private testing. Semua metode pengujian representasi menggunakan dataset ini menggunakan 3 task yang telah disebutkan diatas.
Video
Sementara itu untuk video ada beberapa dataset yang sering digunakan yaitu: YFCC100M, SceneNet RGB-D, Moment in Time, Kinetics, AudioSet, KITTI, UCF101, dan HMDB51.
Sampai disini dulu, besok insyaAllah akan saya lanjutkan dengan pembahasan berbagai metode learning fitur pada image. Semoga Bermanfaat!
Papernya bisa dilihat pada link berikut :