Saya lanjutkan pembahasan tentang kuliah Ishan Misra tentang Self supervised learning untuk image. Sebelumnya kita telah membahas tentang teknik contrastive learning dan clustering dan avid cma. Hari ini kita lanjutkan tentang teknik Distillation. Teknik distilasi termasuk teknik untuk memaksimalkan similarity. Ada 2 teknik distillation yang akan dibahas yaitu BYOL dan SimSiam.
Jika kita memiliki fθstudent(I)=fθteacher(augment(I))
f theta (I) kita inginkan similar dengan f theta augmented (I). Ada beberapa cara melakukannya, kali ini kita akan menggunakan konsep distillation student dan teacher. Kita akan menghitung embedding dari student untuk image I, dan menghitung embedding teacher untuk image I augmented, dan kita akan memaksa similarity dari keduanya. Bila student dan teacher sama (identik) maka kita akan memiliki solusi trivial.
Untuk mencegahnya kita menggunakan konsep asimetri. Asimetri ini bisa berada pada 2 cara:
- Asimetri learning rule antara student dan teacher. Dimana weight student dan teacher tidak diupdate dengan cara yang sama ketika kita melakukan backpropagation
- Asimetri arsitektur. Arsitektur student dan teacher berbeda. Sehingga membentuk asimetri yang bisa mencegah solusi trivial.

BYOL
Metoda distilasi pertama adalah BYOL. Ada tiga asimetri pada BYOL sebagai berikut:
- Kita memiliki encoder student dan ditambahkan prediction head yang kemudian menghasilkan embedding. Dari encoder teacher kita melakukan feed forward image kemudian kita langsung mendapatkan embedding. Sehingga terlihat ada perbedaan arsitektur pada student dan teacher.
- Kemudian backpropagasi gradient hanya melalui encoder student, tanpa melalui encoder teacher. Ini berarti terdapat asimetri pada learning rate.
- Perbedaan ketiga adalah pada weights encoder student dan encoder teacher. Encoder teacher didapatkan sebagai moving average dari encoder student. Seperti pada MoCo.
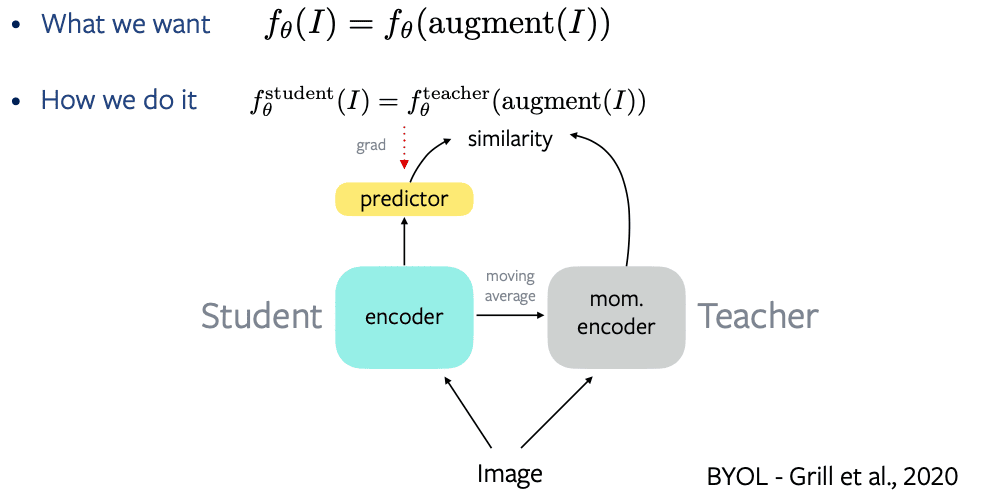
Dengan 3 asimetri ini kita dapat mencegah solusi trivial.
SimSiam
Pada tahun 2020 muncul simsiam. Menurut metode ini kita gak perlu 3 asimetri, cukup 2 aja. Menurut simsiam, kita gak perlu set weights yang berbeda. Jadi pada SimSiam memiliki weights yang sama sehingga kita hanya memiliki 2 asimetri
- Arsitektur student dan tambahan predictor head
- Pada learning rate, ketika backpropagasi, gradient hanya melalui encoder student. Tidak melalui encoder teacher. Setelah setiap epoch, weight dari student, dikopi ke encoder teacher.
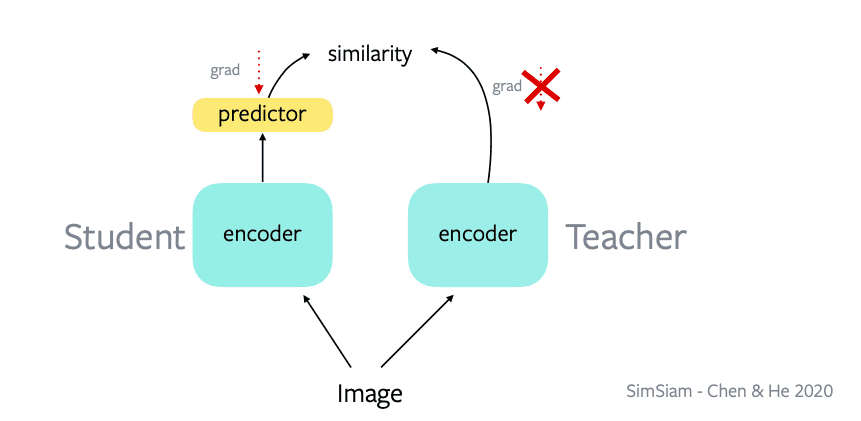
Ketika melakukan forward pass kita hitung embedding student dan teacher, sehingga embeddingnya identik. Tapi pada backward pass kita tidak mengupdate embedding teacher. Kemudian pada forward pass berikutnya kita kopikan embedding student ke teacher.
Materinya bisa dilihat disini:
https://atcold.github.io/NYU-DLSP21/en/week10/10-2/
slidenya ada disini:
https://drive.google.com/file/d/1BQlWMVesOcioW69RCKWCjp6280Q42W9q/edit
Videonya:
Satu tanggapan untuk “Distillation SSL- Ishan”
Great content