Saya lanjutkan pembahasan paper Self Supervised Visual Feature dari Jing dan Tian. Sebelumnya telah dibahas tentang context based image feature learning. Sekarang saya lanjutkan tentang free semantic label.
Free semantic label adalah label yang didapat tanpa proses pelabelan manual. Secara umum label free semantic seperti segmentation masks, depth images, optic flows, dan surface normal dari sebuah gambar dapat diperoleh dari proses rendering dengan game engine. Selain itu dapat juga digenerate dari metode
hard-code. Label semantic digenerate secara otomatis. Metode dengan dataset sintetik atau menggunakannya pada sejumlah besar gambar tidak berlabel termasuk metode self supervised.
Label digenerate dengan game engine
Dari model-model dengan berbagai obyek dan layout lingkungan, game engine dapat melakukan render gambar secara realistis. Game engine dapat menyediakan label pada tingkat pixel secara akurat. Engine dapat menggenerate dataset besar dengan ekonomis. Engine seperti Airsim dan Carla telah digunakan untuk menggenerate dataset sintetik besar dengan label semantik tingkat tinggi seperti depth, contours,
surface normal, segmentation mask, dan optical flow. Contoh gambar RGB dengan label yang digenerate secara akurat bisa dilihat pada gambar berikut:
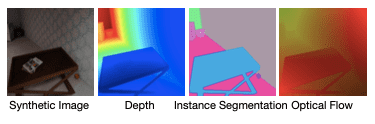
Walaupun lebih ekonomis, masih ada gap antara gambar sintetik dan gambar asli. Sehingga ConvNet yang ditraining hanya pada gambar sintetik, tidak dapat diimplementasikan langsung pada gambar asli (real world).
Untuk menggunakan dataset sintetik pada fitur learning self supervised, convnet ditraining dengan label semantik.
Untuk mengatasi gap, Ren dan Lee mengajukan metode adaptasi unsupervised feature space berbasis adversarial learning. Seperti pada gambar dibawah network memprediksi surface normal, depth, dan instance contour untuk synthetic images dan sebuah discriminator network D digunakan untuk meminimalkan perbedaan feature space antara data sintetik dan real-world.
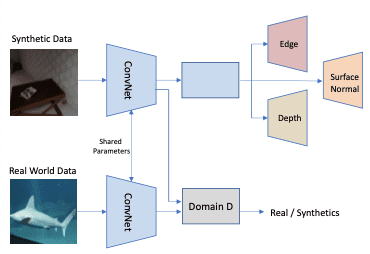
Dengan adversarial training dan label semantik yang akurat, network dapat menangkap fitur virtual dari gambar asli (real-world images).
Dibandingkan dengan pretext task lain yang memaksa ConvNets untuk mempelajari fitur semantik, metode ini melakukan training dengan label semantik yang akurat. Sehingga ConvNets dipaksa untuk mempelajari fitur yang berkaitan dengan obyek pada gambar.
Label dari hard-code program
Menggunakan hard-code program label semantik seperti salience, foreground mask, contours dan depth dapat digenerate secara otomatis. Dengan cara ini, dataset besar dengan label semantik yang digenerate dapat digunakan untuk pembelajaran fitur self-supervised.
Metode ini memiliki 2 tahap:
- Generate label dengan menggunakan program
- Training convnet dengan label yang telah digenerate
Beberapa program telah digunakan untuk menggenerate label untuk task segmentasi obyek foreground, deteksi edge, prediksi depth relatif. Pathak dkk mengajukan metode training convnet untuk melakukan segment obyek foreground pada setiap frame dari sebuah video, dimana label adalah mask dari obyek yang bergerak pada video.
Li dkk mengajukan metode training untuk prediksi edge, dengan label adalah motion edge dari flow field dari video. Jing dkk melakukan training untuk prediksi scene depth relatif dimana label digenerate dari optical flow.
Metode- metode diatas menggunakan hard-code detector yang berbeda seperti edge detektor, salience detektor, relative detektor dll. Perbedaan metode ini dengan metode self-supervised lain adalah sinyal supervisinya adalah label semantik yang mendorong ConvNet untuk mempelajari fitur semantik. Namun kekurangan label semantik dari hard-code detektor adalah banyak noise.
Sampai disini dulu, selanjutnya akan dibahas perbandingan kinerja dari metode self-supervised yang ada. Semoga Bermanfaat!
Papernya bisa dilihat pada link berikut :