…postingan ini lanjutan dari catatan kuliah IAIS
materi berikutnya adalah sharing dari Dr. Anto Satriyo Nugoro tentang tips dan trik memakai machine learning untuk pattern recognition. Pattern Recognition adalah proses mengasosiasikan suatu pattern (pola) dengan kategori. Contoh sistem OCR untuk mengenali tulisan tangan, sistem untuk mengenali wajah dari sketsa.
Arsitektur pattern recognition:
- Observasi : proses mengubah pattern ke dalam format yang bisa diolah oleh mesin
- Preprocessing : melakukan proses awal agar data mudah diolah pada tahap selanjutnya
- Feature Extraction : memakai seluruh hasil dari observasi dan memetakan bagian yang bermanfaat ke dimensi yang lebih rendah lewat suatu fungsi
- Feature Subset Selection : memilih subset “terbaik” dari atribut/feature data ditinjau dari kontribusinya terhadap class-separability
- Classifier/Klasifikasi : memetakan hasil reduksi dimensi ke kategori tertentu
Beberapa metode klasifikasi:
- Naïve Bayes
- K-Nearest Neighbor Classifier
- Multilayer Perceptron
- Deep Learning; classifier dan feature ekstraction digabung (contoh : Residual Neural Network – Microsoft);
Naive Bayes: Klasifikasi dilakukan dengan menghitung Posterior Probability suatu class. Untuk menghitung Posterior Probability, diperlukan informasi Prior Probability dan Likelihood. Contohnya digunakan untuk mendeteksi spam pada email.
- Posterior = (Prior x Likelihood)/Evidence. Biasanya selalu dilakukan penyesuaian prior probability dan likelihood.
K-Neares Neighbour Classifier: dari sebuah data yang terdiri dari n sampel akan diklasifikasikan ke dalam c kelas. Jumlah C ditentukan terlebih dahulu. Kemudian klasifikasi akan dilakukan dengan menghitung jarak terdekat dari sampel ke C.
- Perlu memori yang besar
- Cukup handal
- Sering digunakan sebagai kompetitor atau pembanding dari hasil metode lain
Multilayer Perceptron: Misalnya dari sebuah input data dirancang sebuah sistem yang terdiri dari beberapa layer network untuk menghasilkan output tertentu. Pada layer tersebut ada weight tertentu. Bila output belum sesuai maka weight akan dimodifikasi, dan dilakukan iterasi ulang, hingga mencapai output yang diinginkan. Teknik ini disebut juga backpropagation. Contohnya sistem handwriting character recognition pada faximile.
Deep Learning: menggunakan prinsip neural network, dengan hidden layer.
-
AlexNet memiliki 5 convolutional layers, Visual Geometry Group (VGG) network memiliki 19 layers sedangkan GoogLeNet (inception) memiliki 22 layer
-
Residual Network dikembangkan oleh Microsoft
-
Versi original : terdiri dari 152 layer
-
https://towardsdatascience.com/an-overview-of- resnet-and-its-variants-5281e2f56035
Dalam merancang sebuah sistem pengenalan pola, alurnya adalah
- Memahami karakteristik data dan masalah yang akan diselesaikan. Pertimbangkan tentang Missing data: apakah ada data yang hilang; Apakah ada data nominal? apakah perlu Normalisasi data, apakah ada Class imbalancy pada data
- Menentukan ekstraksi fitur/seleksi fitur (handcrafted feature). apabila memakai deep learning, ekstraksi fitur dilakukan secara otomatis pada modul classifier
- Menentukan metode klasifikasi
- Menentukan metode evaluasi
Apakah cukup dengan menggunakan classifier terbaru? menurut beliau tidak. Memahami data dan karakteristiknya menjadi syarat utama sebelum metode klasifikasi ditentukan. Wajib menganalisa karakteristik data agar pengolahan berlangsung secara benar dan optimal
-
untuk Data yang jumlah sedikit, umumnya metode classifier akan memiliki akurasi yang sama. Tidak banyak perbedaan klasifikasi boundary yang dibentuk. Contoh: data biomedis, bencana alam
-
Data dalam jumlah besar: Lihat dulu,apakah data tidak ada yang redundant? Apakah linearly separable ?
-
Jumlah data tiap class apakah “seimbang” atau terdapat kasus imbalanced ?
-
Apakah dimensi data bisa direduksi ? Mungkinkah proses pelatihan dilakukan dengan data yang lebih kecil dimensinya ?
-
Apabila system diagnosis (contoh) akan dipakai oleh dokter, apakah hasil ekstraksi fitur diperlukan ?
Ada 4 jenis atribut (Fitur):
- Nominal: contoh: nomer ID, warna mata, kodepos ;
- Ordinal: contoh: peringkat (level pedas makanan 1-5; tinggi badan (tinggi, sedang, rendah))
- Interval: contoh: tanggal kalendar, suhu
- Rasio: contoh: panjang, waktu, suhu dalam kelvin
Dalam atribut normal, perlu kehati2an. Seringkali terjadi kesalahan dalam menghitung jarak. Baiknya menggunakan (1-of-c coding)
Kemudian perlu juga melakukan normalisasi data, contohnya karena perbedaan satuan bisa saja menghasilkan distance yang salah. Ubah nilai feature sehingga memiliki range yang sama.
Memiliht Feature yang relevan: memilih subset “terbaik” dari atribut/feature data ditinjau dari kontribusinya terhadap class-separability
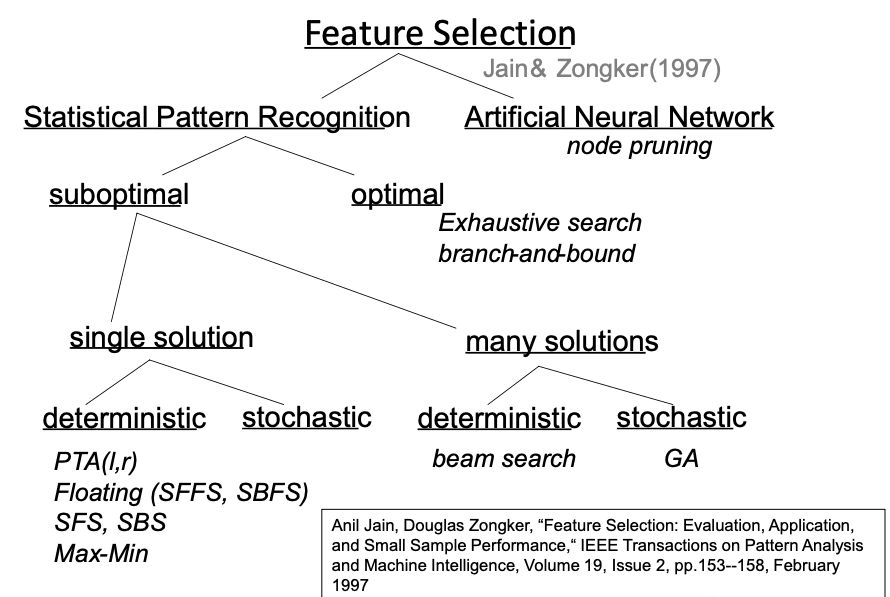
Bagaimana subset fitur dipilih? (mengikuti taksonomi berikut:
SFS: sequential Forward Selection: memilih feature secara sekuensial yang paling signifikan dengan kondisi saat ini. Metode ini memakai pendekatan wrapper. Kualitas subset fitur yang dipilih dievaluasi memakai akurasi suatu classifier. (A.W,Whitney,”A direct method of nonparametric measurement selection,” IEEE Trans. Comput.20,pp.1100-1103, 1997.)
SBS: Sequential Backward Selection: Menghilangkan feature secara sekuensial yang paling tidak signifikan dengan kondisi saat ini. (Marill,T,D.M.Green,”On the effectiveness of receptors in recognition system,” IEEE Trans. Inform. Theory 9, pp.11-17, 1963.)
SFFS: Sequential Floating Forward Selection: menjalankan beberapa langkah SBS setelah SFS; Solusi terhadap nesting problem pada algoritma SFS dan SBS Hasil terbaik dibandingkan metode yang lain (Jain & Zonker, 1997) namun komputasi lebih kompleks.
Kriteria Evaluasi Subset:
- Wrapper: Memakai akurasi classifier untuk mengevaluasi performance dari subset yang dipilih. Masalah : bagaimana memilih classifier? komputasi lebih kompleks
- Filter: Berbasis distance/information measures yang merupakanintrinsic properties pada data; lebih mudah; Tepat dipakai untuk data berdimensi sangat tinggi
Kriteria Fisher memilih salah satu feature secara independent yang paling baik dalam memisahkan dua class.
Imbalanced Dataset: suatu kelas/kategori memiliki jumlah sampel jauh lebih banyak daripada kelas/kategori yang lain; Contoh:munculnya super-cooling fog, prediksi abnormality pada penyakit. Solusi:
- Modifikasi data training: upsampling, downsampling
- Modifikasi metode
- Kombinasi
Hati-hati dengan formula untuk mengevaluasi hasil : secara umum geometric mean lebih disukai daripada arithmetical mean. Kemudian dia memberi contoh tentang sistem prediksi kabut yang dibuatnya di Jepang.
Performance Evaluation, model assessment:
- Generalisasi: prediksi kapabilitas suatu classifier pada data test yang independent
- Model selection:perkiraan kinerja berbagai model yang berbeda untuk menentukan model terbaik
- Model Assessment : memakai model yang dipilih, untuk mengukur kinerjanya (generalization error) dari tingkat error pada data yang lain dengan yang dipakai di atas
Best Approach: Data dibagi 3: traning set, validasi set, dan testing set; cocok untuk jumlah data besar
Metode Hold-out (H) : data dibagi 2: Training dan testing set; cocok utk jumlah data besar.
Metode K-fold Cross Validation (CV): data dibagi 5;
Untuk bagian k (ketiga di atas), kami menyesuaikan model ke bagian K – 1 lainnya dari data, dan menghitung kesalahan prediksi dari model yang dipasang saat memprediksi bagian ke data. Kami melakukan ini untuk k = 1, 2,. . . , K dan menggabungkan perkiraan K dari kesalahan prediksi;
Validasi Cross Leave-One-Out: K = N (jumlah sampel)