Pada tulisan sebelumnya telah dibahas tentang teknik Barlow Twins. Berikut ini adalah penjelasan lanjutan tentang Barlow Twins dari Ishan Misra.
Hipotesis tentang efficient coding diajukan olah Horace Barlow pada tahun 1961 sebagai model teoritis dari pengkodean sensor pada otak. neuron pada otak kita saling berkomunikasi dengan mengirimkan impuls elektrik yang disebut spike. Menurut Barlow, spikes pada sistem sensor membentuk sebuah kode neural yang merepresentasikan informasi sensor secara efisien. Yang dimaksud Barlow efisien adalah kodenya meminimalkan jumlah spikes yang dibutuhkan untuk mengirimkan sebuah sinyal
Pendekatan Self-supervised learning yang berhasil adalah dengan mempelajari representasi yang invariant terhadap gangguan dari sampel input. Walaupun begitu pendekatan ini memiliki hambatan yaitu timbulnya solusi trivial konstan.
Metoda Barlow twin mengajukan sebuah fungsi obyektif yang dapat menghindari hal ini dengan cara mengukur matriks cross-corelation antara output dari dua jaringan identik yang mendapat input versi dari sampel yang sedikit berbeda (distorted) dan membuat keduanya semakin dekat ke matriks identitas.
Prinsip reduksi redundansi barlow diterapkan pada sebuah pasangan jaringan identik. Tujuan dari fungsi obyektif adalah menghitung matriks cross-corelation antara fitur output daru dua jaringan identik yang mendapat input versi berbeda (distorted) dari sebuah batch sampel dan mencoba untuk membuat matrix ini sedekat mungkin dengan matriks identitas. Hal ini membuat vektor-vektor representasi dari versi-versi berbeda dari sebuah sampel menjadi mirip, dan meminimalkan redundansi antara berbagai komponen dari vektor-vektor ini, seperti gambar di bawah.
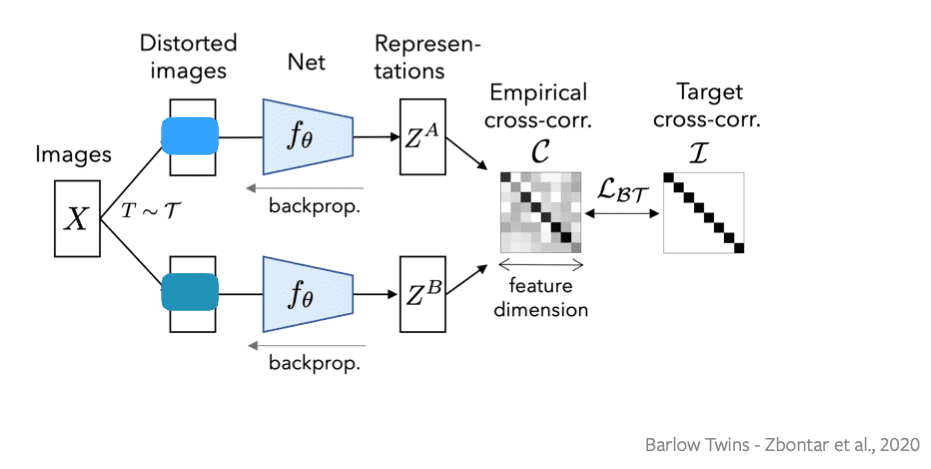
Secara formal, jaringan ini menghasilkan dua versi (view) berbeda dari semua gambar pada sebuah batch X. View yang berbeda ini didapatkan melalui sebuah distribusi dari augmentasi data T. Kedua batch dari distorted views YA dan YB kemudian dimasukan ke fungsi fθ, contohnya sebuah deep network dengan parameter yang dapat ditraining θ, yang menghasilkan batch representasi ZA dan ZB .
Loss function LBT memiliki sebuah invariance dan redundancy reduction:

dimana λ adalah sebuah konstanta yang mengatur seberapa penting loss pertama dan kedua, dan dimana C adalah matrix cross-correlation yang dihitung antara outout-output dari dua jaringan identik sepanjang dimensi batch :

dimana indeks b adalah dari sampel-sampel batch dan i,j adalah dari dimensi vektor dari output network. C adalah sebuah matriks kotak dengan ukuran dimensi output network. Dengan kata lain, pengertian invariance dari objective dengan berusaha menyamakan elemen diagonal dari matriks cross-correlation matrix menjadi 1, membuat representasi invariant terhadap distorsi yang digunakan
Istilah pengurangan redundansi, dengan cara menyamakan elemen diluar diagonal dari matriks cross-correlation matrix menjadi 0, mendekorelasi komponen vektor yang berbeda dari representasi. Dekorrelasi ini mengurangi redundansi antara unit output, sehingga unit output berisi informasi non-redundan tentang sampel.
Materinya bisa dilihat disini:
https://atcold.github.io/NYU-DLSP21/en/week10/10-2/
slidenya ada disini:
https://drive.google.com/file/d/1BQlWMVesOcioW69RCKWCjp6280Q42W9q/edit
Videonya: