Mari kita lanjutkan bahasan tentang paper Big Self-Supervised Models Advance Medical Image Classification, karya Azizi dkk. Pada tulisan sebelumnya telah dibahas tentang proses fine-tuning. Kali ini saya lanjutkan bahasan tentang hasil eksperimen.
Eksperimen yang dilakukan azizi, dilakukan untuk menguji apakah metode self-supervised yang diusulkan menghasilkan performa lebih baik dibandingkan metode supervised. Satu aspek penting pada transfer learning dengan self-supervised adalah pemilihan dataset tidak berlabel yang tepat.
Azizi menguji beberapa arsitektur berbeda diantaranya ResNet-50 (1×), ResNet-50 (4×) dan ResNet- 152 (2×) . Kemudian menguji 3 skenario pada data medis:
- Menggunakan dataset ImageNet saja
- Menggunakan dataset tidak berlabel yang spesifikus (contohnya dataset Derm dan CheXpert)
- Initialisasi pretraining dari model self-supervised ImageNet yang kemudian dilanjutkan dengan pre-training pada dataset yang spesifik contohnya ImageNet → CheXpert dan ImageNet → CheXpert.
Hasil pengujian menunjukan performa terbaik pada skenario 3. Model yang lebih besar menghasilkan performa lebih baik.
Pengujian berikutnya adalah dengan multi-instance contrastive learning (MICLe) dan menggunakan beberapa gambar pada sebuah kasus dan dipelajari apakah meningkatkan performa pretraining.
Tabel berikut membandingkan performa pada dataset kulit dengan MICLe dan tanpa MICLe:
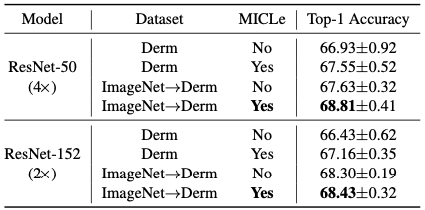
Dari tabel terlihat MICLe meningkatkan performa model dibandingkan metode SimCLR.
Percobaan berikutnya adalah dengan menggunakan sampel negatif lebih banyak dan training lebih lama dengan 1000 epochs dan batch size yang lebih besar (1024). Dari hasil pengujian hasil model MICLe menghasilkan performa lebih baik .

Dilakukan pengujian juga untuk membandingkan dengan model yang dibangun Kolesnikov dkk yaitu ResNet-101 (3×) yang di pretrained pada ImageNet21-k. Model ini dinamakan Big Transfer (BiT) bisa diakses di tautan https://github.com/ google- research/big_transfer
Model ini melakukan modifikasi pada arsitekur, dan ditraining pada dataset yang lebih besar (14 juta gambar berlabel dengan 21 ribu kelas). Dibandingkan dengan model MICLe dengan dataset 1 juta gambar pada ImageNet.
ResNet-101 (3×) memiliki parameter 382 juta, sementara ResNet-152 (2×) memiliki 233 juta parameter. Ternyata model MICLe model menghasilkan performa lebih baik dibandingkan model BiT model.
Pengujian berikutnya unutk mengujia seberapa robust model terhadap perubahan distribusi data. Pada pengujian ini digunakan model post-pretraining dan end-to-end fine-tuning (seperti CheXpert dan Derm) untuk melakukan prediksi pada dataset yang berubah tanpa melakukan fine-tuning ulang (zero-shot transfer learning).
Dari hasil pengujian ternyata model self-supervised meningkatk generalisasi model. Sementara itu hanya menggunakan model ImageNet untuk pretraining self supervised, performa model lebih rendah.
Kemudian dilakukan pengujian efisiensi label pada model self-supervised. Caranya dengan melakukan finetuning model pada potongan data training berlabel yang berbeda. Potongan labelnya berkisar antara 10% – 90% untuk dataset Derm dan CheXpert. Percobaan diulang beberapa kali menggunakan parameter terbaik dan dirata-ratakan.
Pretraining dengan model self-supervised dapat meningkatkan efisiensi label untuk klasifikasi gambar medis. Performa pada semua potongan (fractions) lebih baik dibandingkan model supervised. MICLe secara proporsi menghasilkan performa cukup baik pada label yang sedikit. MICLe berhasil menghasilkan performa sama dengan baseline hanya dengan 20% data training untuk ResNet-50(4×) dan 30% untuk ResNet- 152 (2×).
Arah penelitian kedepan adalah menguji model pada dataset tidak berlabel yang besar. Selain itu transfer pada multimodal. Dengan demikian telah selesai pembahasan paper ini.
Papernya bisa dilihat disini:
https://ieeexplore.ieee.org/document/9710396
Semoga Bermanfaat!
Tulisan sebelumnya tentang fine-tuning