Saya lanjutkan bahasan tentang kuliah Ishan Misra tentang berbagai metode Self-Supervised Learning (SSL). Pada tulisan sebelumnya kita telah mengenal tentang permasalahan solusi trivial pada pretext task, serta 2 metode SSL yang digunakan untuk mengatasinya yaitu maximize similarity dan redundance reduction. Kemudian telah dibahas juga tentang metode contrastive learning (CL), seperti PIRL, SimCLR, memory bank dan Moco. Hari ini kita akan lanjutkan teknik SSL berukutnya yaitu clustering.
Bagaimana hubungan Contrastive learning dan clustering?
Pada Constrastive Learning, setiap sampel memiliki hubungan positif dan negatif, tujuan dari learning task adalah untuk mencoba mendekatkan positive embedding dan menjauhkan negative embedding. Dan kita mengulang proses ini pada setiap sampel positif. Jadi bisa dikatakan kita mengelompokan sampel kedalam fitur space.
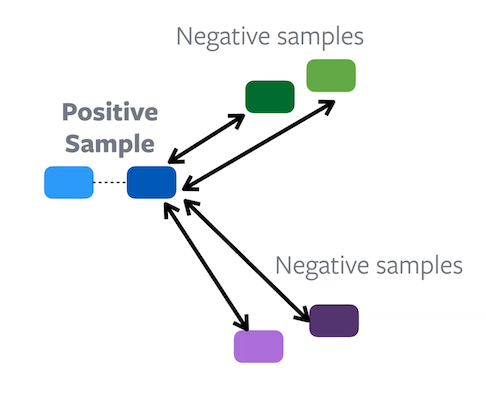
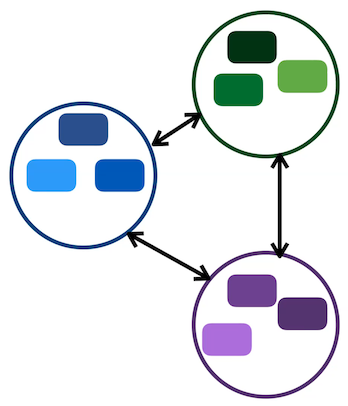
Pada gambar diatas terlihat contrastive learning mengelompokan sampel kedalam kelompok di feature space. Misalnya kelompok biru adalah embedding dari sampel yang kita dapatkan dari augmentasi dari sampel yang sama, demikian juga yang hijau dan ungu. Kita ingin embedding ini mendekatkan sampel satu sama lain, namun menjauhkan dari training sampel.
Sementara itu clustering, mempunyai cara yang lebih mudah untuk mengelompokan sampel, karena secara alamiah clustering membentuk kelompok pada feature space.
Ada 3 teknik clustering, SeLA, SwAV dan DeepCluster.
SwAV
Algoritma SwAV (Swapping Assignments between Views) adalah sebuah metode clustering online. Cara kerjanya adalah untuk maximize the similarity dari sebuah gambar I dan augmentasi dari gambar augment(I). Dengan cara ini SwAV memastikan gambar I dan augmentasinya berada pada cluster yang sama.
fθ(I)=fθ(augment(I))
Pada kasus ini, sampel dan hasil augmentasinya memiliki keterangan warna yang berbeda. Kemiripan dari embedding setiap sampel pada setiap prototipe (cluster-center) dihitung. Sampel kemudian dikelomopokan ke prototipe dengan kemiripan yang paling tinggi. Tujuan network ini adalah untuk mengelompokan gambar dan hasil augmentasinya kedalam prototipe yang sama. Bila gambar dan hasil augmentasinya berada dalam kelompok yang sama, maka nilai similaritynya adalah maksimal. Contoh groupingnya bisa dilihat pada gambar berikut:
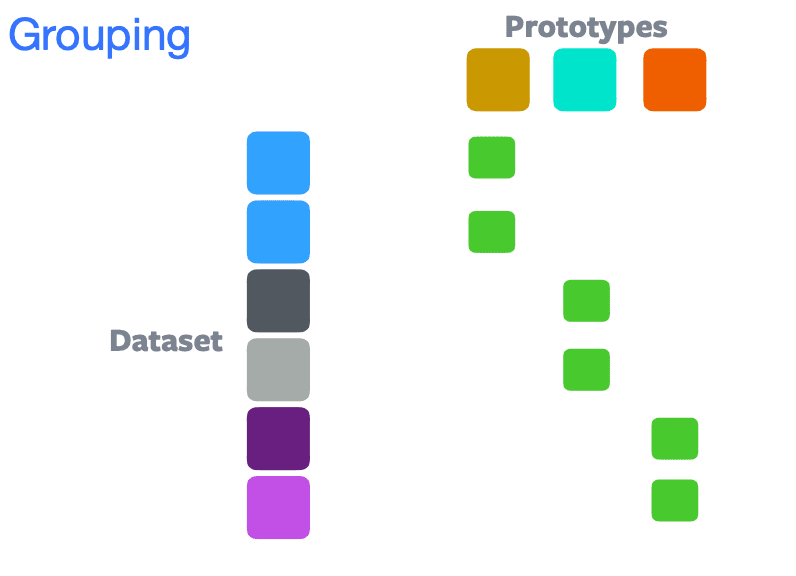
Pada gambar diatas terlihat kita berusaha mengelompokan warna berdasarkan kemiripannya kedalam 3 kelompok (prototipe)
Apakah teknik ini bisa menghasilkan solusi trivial?
Bisa terjadi. Solusi trivial terjadi dimana semua sampel dikelompokan ke dalam kelompok/cluster/protipe yang sama. Ini menyebabkan kerusakan representasi pada setiap input. Contohnya bisa dilihat pada gambar berikut:
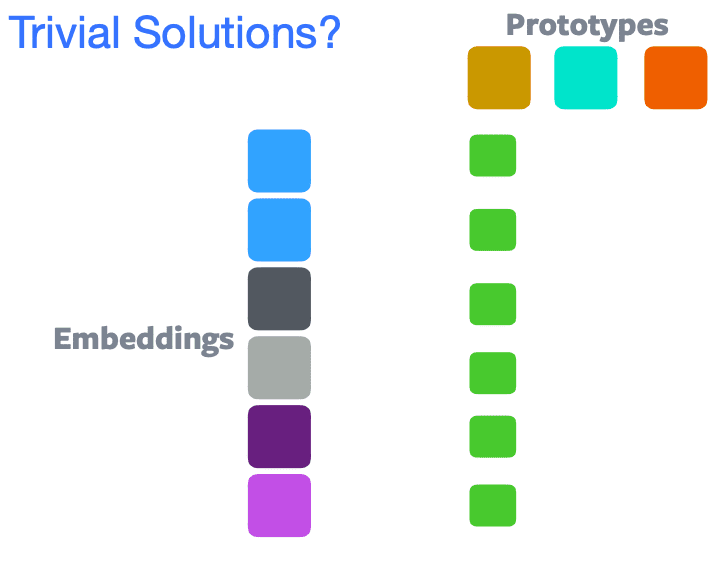
Pada gambar diatas terlihat, semua input dikelompokan hanya pada satu prototipe. Untuk mencegah terjadinya solusi trivial kita dapat mengontrol proses clustering. Dua teknik yang bisa digunakan diantaranya:
- Equipartition constraint
- Soft Assignment
Sampai disini dulu, pembahasan tentang 2 teknik diatas akan saya lanjutkan besok insyaAllah. Semoga Bermanfaat!
Materi kuliahnya: