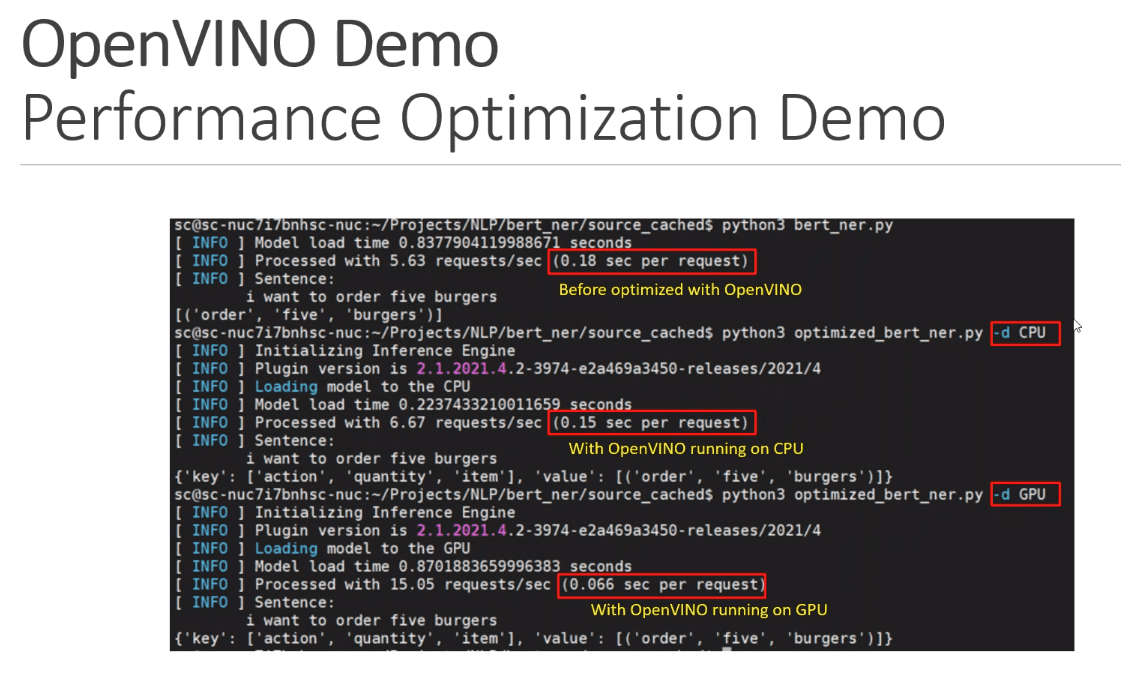
Saya lanjutkan pembahasan tentang paper Self-Supervised Visual Feature Learning with Deep Neural Network: A Survey dari Longlong Jing dan Yingli Tian. Pada tulisan sebelumnya telah dibahas tentang macam-macam teknik learning feature pada image, diantaranya dengan metode image generation dengan inpainting. Sekarang kita lanjutkan tentang metode image generation dengan Super-resolution.
Image super-resolution (SR) adalah sebyah task untuk meningkatkan resolusi dari sebuah gambar. Dengan menggunakan jaringan Fully convolutional, kita bisa menghasilkan gambar dengan resolusi tinggi dari input gambar dengan resolusi rendah. SRGAN adalah sebuah “generative adversarial network for single image super-resolution” yang diajukan oleh Ledig dkk. Metode yang dilakukan adalah dengan perceptual loss, yang terdiri dari adversarial loss dan sebuah content loss. Dengan perceptron loss, SRGAN mampu menghasilkan tekstur foro yang realistik dari input gambar yang downsampled (resolusi rendah).
Metode ini memiliki 2 jaringan: generator dan diskrimantor
Generator bertugas meningkatkan resolusi dari gambar input, sementara diskriminator bertugas untuk membedakan apakah gambar input adalah output dari generator. Loss function dari generator adalah L2 Loss pixel-wise ditambah content loss yaitu kemiripan dari fitur gambar resolusi tinggi hasil prediksi dan gambar asli dengan resolusi tinggi. Sementara loss dari diskriminator adalah binary classification loss.
Dibandingkan dengan jaringan lain yang menggunakan metode meminimalkan Mean Squared Error (MSE) yang menghasilkan rasio sinyal to noise tinggi namun tidak memiliki detail frekuensi tinggi, SRGAN mampu menhasilkan gambar dengan detail resolusi tinggi. Karena adversarial loss menghasilkan output ke gambar asli oleh dari jaringan diskriminator.
Jaringan dengan resolusi tinggi ini dapat mempelajari fitur semantik dari gambar. Seperti metode GAN lainnya, parameter dari discriminator network dapat ditransfer ke downstream task.
Sampai disini dulu, besok insyaallah saya lanjutkan dengan metode image generation dengan Colorization.
Papernya bisa dilihat pada link berikut :